[DATA SCIENCE]
데이터사이언스 > 모델링 > 새로운 확률변수 > 확률변수의 제곱합과 곱과 비
결정계수
[Q&A]
스프레드시트에서 정리한 정형데이터에서 데이터를 속성에 따라 분류하면
범주형데이터, 순서있는 범주형데이터, 이산형데이터, 연속형데이터 이 중에서 이산형데이터와 연속형데이터는 수치로 나타나는 양적데이터입니다.
데이터 프레임
데이터 프레임은 열과 행으로 구성된 테이블 형태의 데이터 구조로, 다양한 데이터 타입의 값을 저장하고 데이터 분석에 활용됩니다.
데이터에서 확률밀도함수를 피팅하는 방법
개체의 속성으로 확률공간을 모델링
ARTICLE CONTENTS
데이터종류
0:17결정계수
Author
박근철![]() , 양윤원
, 양윤원![]()
DocuHut Co. Ltd., Seoul, Republic of Korea
Citation
Park GC, Yang YW. Data Type. Data Science 2024;1:1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
결정계수는 회귀모델의 적합도를 나타내며, 반응변수와 설명변수의 관계를 회귀기준(점, 선, 면, 초면)을 통해 측정합니다. 잔차표준오차와 결정계수로 모델의 적합도를 평가하며, 결정계수는 회귀식이 데이터의 변동을 얼마나 잘 설명하는지의 비율을 나타냅니다. 총변동 중 회귀식에 의해 설명된 변동의 비율로, 값이 1에 가까울수록 모델의 적합도가 높다고 평가됩니다. 결정계수는 모든 관측값이 회귀직선 주위에 밀집되어 있을 때 높게 나타나며, 이는 추정된 회귀식이 관측값을 잘 대표한다는 의미입니다.
Key Word
결정계수, 회귀모델, 반응변수, 설명변수, 회귀식, 변동
모수와 표본통계량의 추정량
양적 확률변수 $X$의 추정량(estimator)
$X$의 모평균 : $\mu_{X}$
$$\mu_{X} = \dfrac{\sum\limits_{i=1}^{N}X_i}{N}$$
여기서, $N$은 집단크기 : 무한집단인 경우 $N → ∞$
$X$의 표본평균 : $\bar {X}$
$$\bar {X} =\dfrac{\sum\limits_{i=1}^{n}X_i}{n}$$
여기서, $n$은 표본크기
$X$의 모분산 : $\sigma^2_{X}$
$$\sigma^2_{X} = \dfrac{\sum\limits_{i=1}^{N}(X_i – \mu_X)^2}{N}$$
여기서, $\mu_X$는 확률변수 $X$의 모평균
$N$은 집단크기 : 무한집단인 경우 $N → ∞$
$X$의 표본분산 : $S^2_{X}$
$$S^2_{X} = \dfrac{\sum\limits_{i=1}^{n}(X_i{-}\bar{X})^2}{n-1}$$
여기서, $\bar{X}$는 확률변수 $X$의 표본평균
$n$은 표본크기
$X$의 모표준편차 : $\sigma_{X}$
$$\sigma_{X} = \sqrt{\dfrac{\sum\limits_{i=1}^{N}(X_i – \mu_X)^2}{N}}$$
여기서, $\mu_X$는 확률변수 $X$의 모평균
$N$은 집단크기 : 무한집단인 경우 $N → ∞$
$X$의 표본표준편차 : $S_{X}$
$$S_{X} = \sqrt{\dfrac{\sum\limits_{i=1}^{n}(X_i{-}\bar{X})^2}{n-1}}$$
여기서, $\bar{X}$는 확률변수 $Y$의 표본평균
$n$은 표본크기
양적 확률변수 $Y$의 추정량(estimator)
$Y$의 모평균 : $\mu_{Y}$
$$\mu_{Y} = \dfrac{\sum\limits_{i=1}^{N}Y_i}{N}$$
여기서, $N$은 집단크기 : 무한집단인 경우 $N → ∞$
$Y$의 표본평균 : $\bar {Y}$
$$\bar {Y} =\dfrac{\sum\limits_{i=1}^{n}Y_i}{n}$$
여기서, $n$은 표본크기
$Y$의 모분산 : $\sigma^2_{X}$
$$\sigma^2_{Y} = \dfrac{\sum\limits_{i=1}^{N}(Y_i – \mu_Y)^2}{N}$$
여기서, $\mu_Y$는 확률변수 $Y$의 모평균
$N$은 집단크기 : 무한집단인 경우 $N → ∞$
$Y$의 표본분산 : $S^2_{Y}$
$$S^2_{Y} = \dfrac{\sum\limits_{i=1}^{n}(Y_i{-}\bar{Y})^2}{n-1}$$
여기서, $\bar{Y}$는 확률변수 $Y$의 표본평균
$n$은 표본크기
$Y$의 모표준편차 : $\sigma_{Y}$
$$\sigma_{Y} = \sqrt{\dfrac{\sum\limits_{i=1}^{N}(Y_i{-}\mu_{Y})^2}{N}}$$
여기서, $\mu_{Y}$는 확률변수 $Y$의 모평균
$N$은 집단크기 : 무한집단인 경우 $N → ∞$
$Y$의 표본표준편차 : $S_Y$
$$S_{Y} = \sqrt{\dfrac{\sum\limits_{i=1}^{n}(Y_i{-}\bar{Y})^2}{n-1}}$$
여기서, $\bar{Y}$는 확률변수 $Y$의 표본평균
$n$은 표본크기
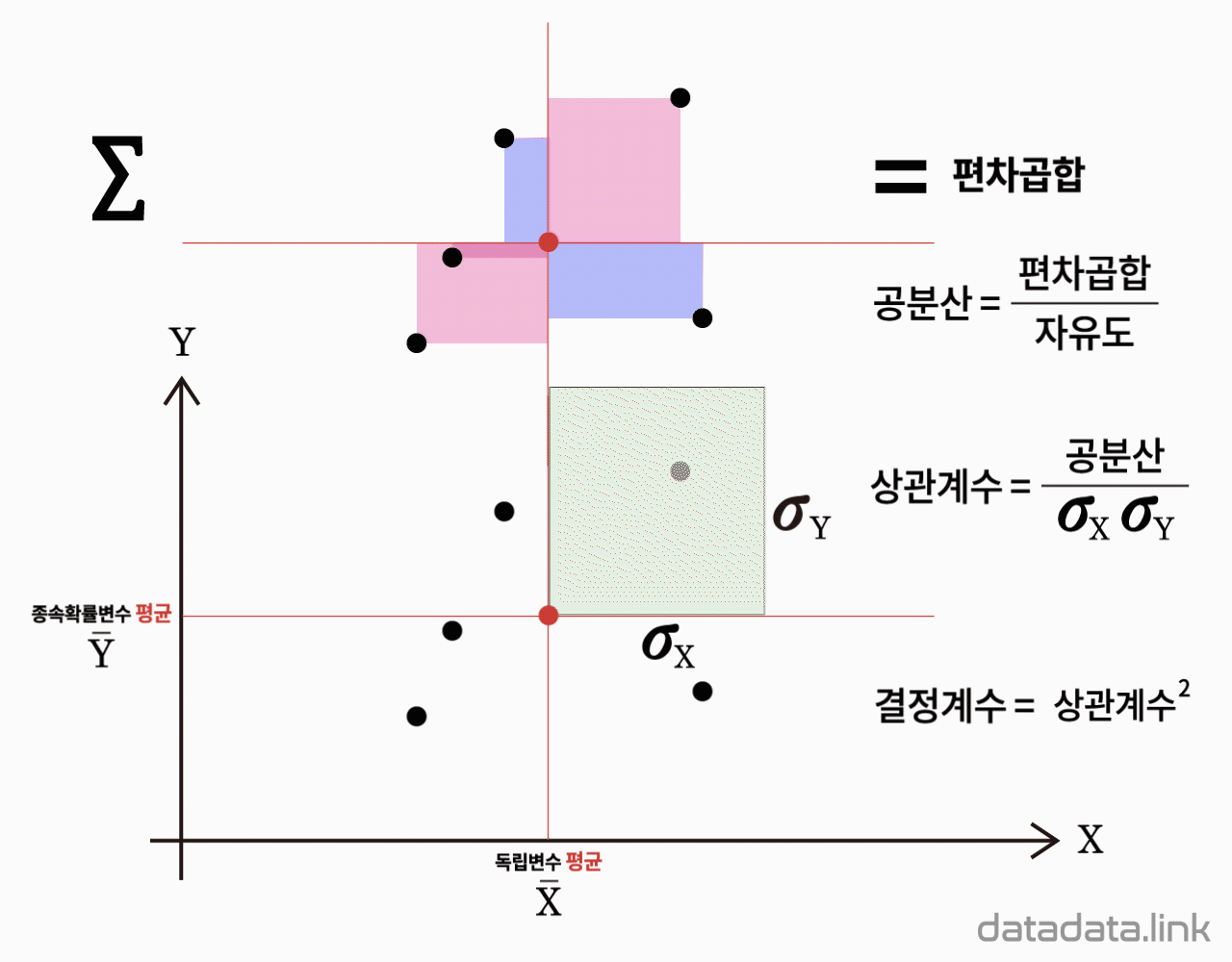
양적 확률변수 $X$, $Y$의 관계 추정량(estimator)
모공분산 : 모$\mathrm{Cov}(X{,}Y)=\sigma_{XY}$
$$\sigma_{XY}=\dfrac{\sum\limits_{i=1}\limits^{N}(X_i{-}\mu_{X})(Y_i{-}\mu_{Y})}{N}$$
여기서, $\mu_{X}$는 확률변수 $X$의 모평균
$\mu_{Y}$는 확률변수 $Y$의 모평균
$N$은 집단크기 : 무한집단인 경우 $N → ∞$
표본공분산 : 표본$\mathrm{Cov}(X{,}Y)=S_{XY}$
$$S_{XY}=\dfrac{\sum\limits_{i=1}\limits^{n}(X_i{-}\bar{X})(Y_i{-}\bar{Y})}{n-1}$$
여기서, $\bar{X}$는 확률변수 $X$의 표본평균
$\bar{Y}$는 확률변수 $Y$의 표본평균
$n$은 표본크기
모피어슨상관계수
$$\rho_{XY}=\dfrac {\sigma_{XY}} {\sigma_{X}\sigma_{Y}}=\dfrac{\dfrac{\sum\limits_{i=1}^{N}(X_i-\mu_X)(Y_i-\mu_Y)}{N}} {\sqrt{\dfrac{\sum\limits_{i=1}^{N}(X_i-\mu_X)^2}{N}}\sqrt{\dfrac{\sum\limits_{i=1}^{N}(Y_i-\mu_Y)^2}{N}}}$$
여기서, $\sigma_{XY}$는 $X$와 $Y$의 모공분산
$\sigma_{X}$는 $X$의 모표준편차
$\sigma_{Y}$는 $Y$의 모표준편차
$\mu_{X}$는 $X$의 모평균
$\mu_{Y}$는 $Y$의 모평균
$N$은 집단크기 : 무한집단인 경우, $N → ∞$
표본피어슨상관계수
$${r}_{XY}=\dfrac {S_{XY}} {S_{X}S_{Y}}=\dfrac{\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar X)(Y_i-\bar Y)}{n-1}} {\sqrt{\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar X)^2}{n-1}}\sqrt{\dfrac{\sum\limits_{i=1}^{n}(Y_i-\bar Y)^2}{n-1}}}$$
여기서, $S_{XY}$는 $X$와 $Y$의 표본공분산
$S_X$는 $X$의 표본표준편차
$S_Y$는 $Y$의 표본표준편차
$\bar X$는 $X$의 표본평균
$\bar Y$는 $Y$의 표본평균
$n$은 표본크기
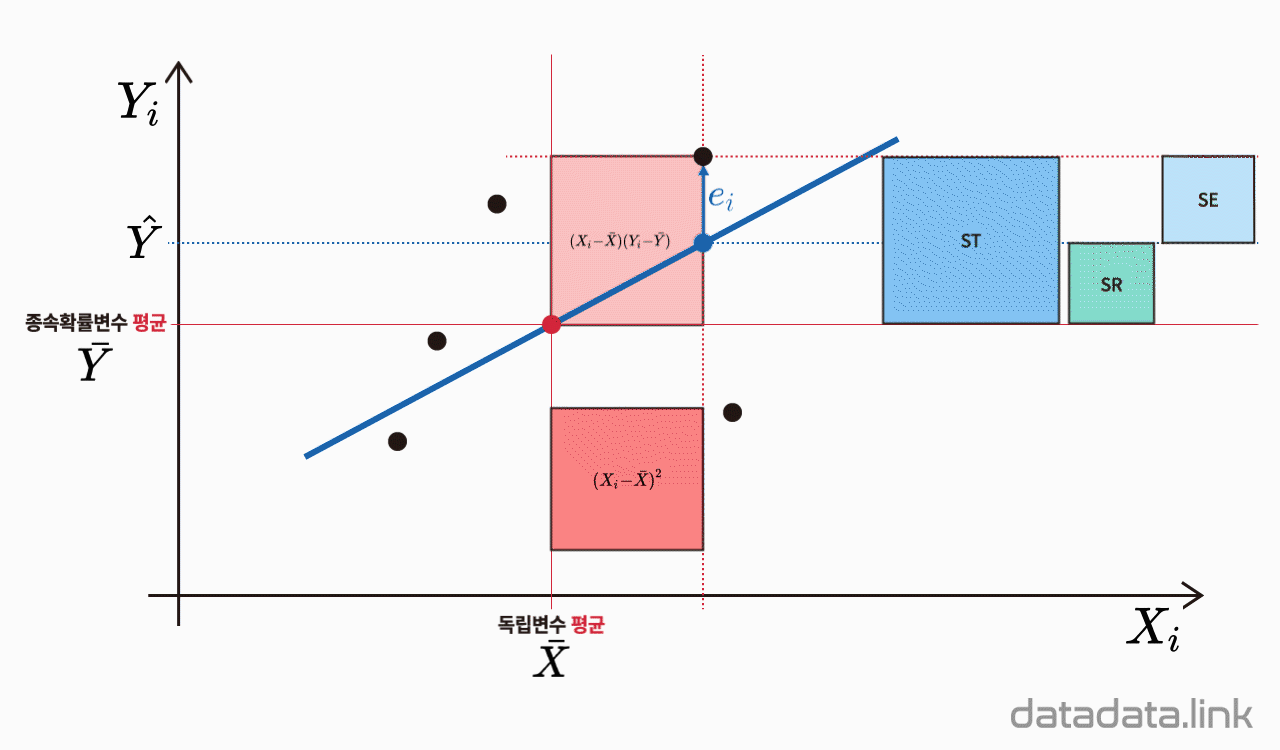
결정계수
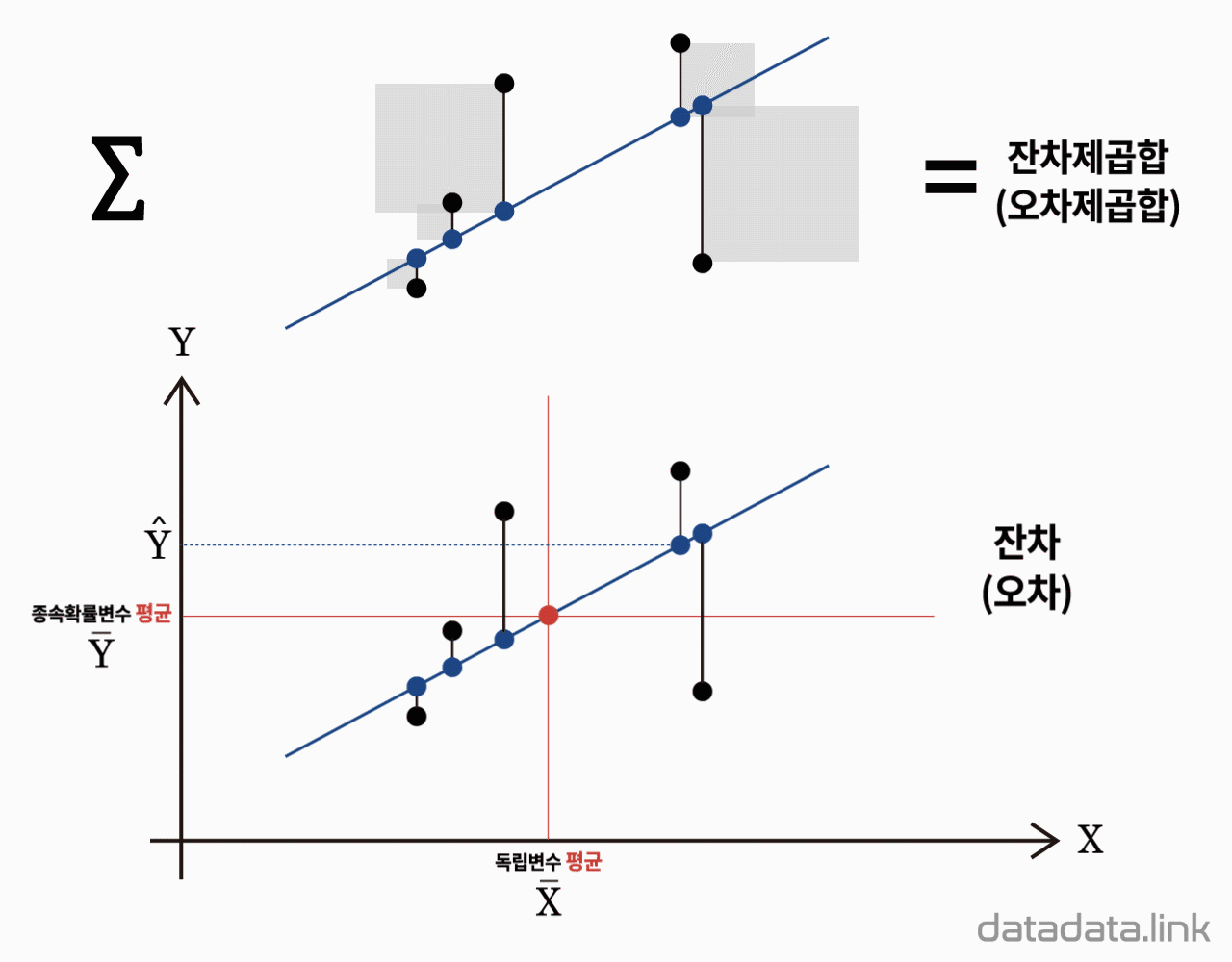
결정계수($R^2$)는 회귀기준(점, 선, 면, 초면)의 적합도를 나타냅니다. 회귀분석의 목적은 반응변수를 설명변수로 설명함에 있습니다. 반응변수와 설명변수의 함수로 표현되는 회귀기준(회귀점, 회귀직선, 회귀평면, 회귀초평면 등)의 적합도는 잔차표준오차(residual standard error)와 결정계수(coefficient of determination)로 나타냅니다. 우선 표본잔차 표집의 분산을 다음과 같이 정의합니다.
$$S_{Res}^2=\dfrac{SS_{Res}}{n-2}=MS_{Res}=\dfrac{1}{n-2}\sum\limits_{i=1}^{n}(Y_{i}-\hat{Y}_{i})^2$$
여기서, $SS_{Res}$은 잔차제곱합
$MS_{Res}$은 잔차제곱평균
$Y_{i}$는 $i$번쨰 결과변수값
$\hat{Y}_{i}$은 $Y_{i}$에서의 회귀량
$n$은 표본크기
잔차표준오차 $S_{Res}$는 $S_{Res}r^2$의 제곱근으로 정의되며 관측값들이 추정회귀직선의 주위에 흩어져 있는 정도입니다. 그리고 $S_{Res}^2$은 $Y$의 값들이 집단의 회귀직선을 중심으로 퍼져있는 정도인 $\sigma_{Res}^2$의 추정량입니다. $S_{Res}$ 또는 $S_{Res}^2$의 값이 작으면 관측값들이 추정회귀직선에 근접해 있음을 나타내고, 반대로 추정회귀직선이 두 변수간의 관계를 잘 대표한다고 할 수 있습니다. 그러나 잔차 표집의 표준오차 $S_{Res}$는 그 값이 “작으면” 좋은 것이지만 어느 정도의 값이 작은 것인지는 분명하지가 않습니다. 또한 $S_{Res}r$의 값은 $Y$의 단위에 따릅니다. 이러한 단점을 없애기 위해서는 상대적인 값이 필요한데, 여기에서 정의할 결정계수는 $Y_{i}$들이 가지는 총변량 중 회귀직선에 의해 설명되는 변량의 비(ratio)로 주어지므로 변량의 종류와 단위에 관계없이 사용할 수 있는 무차원수입니다.
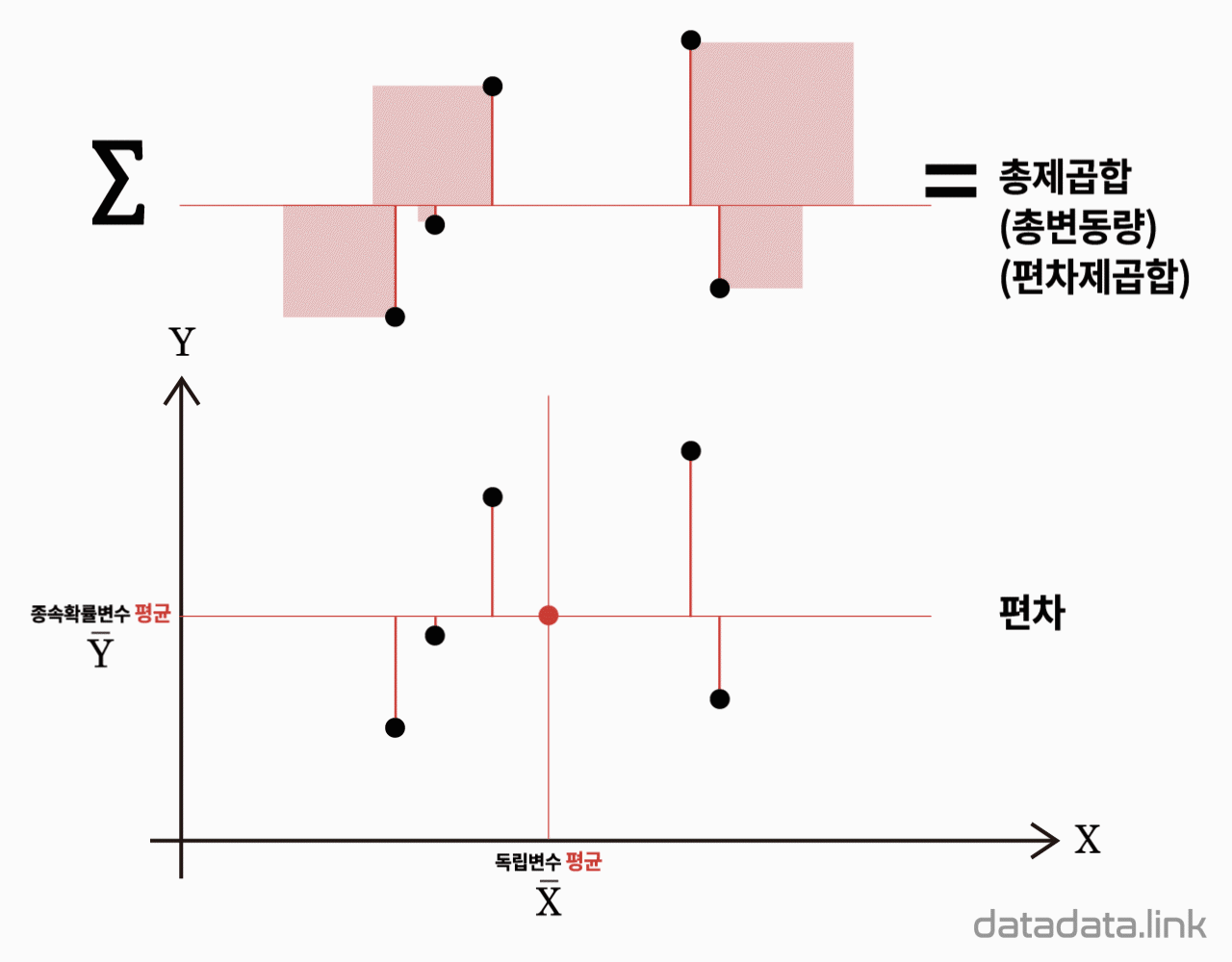
제곱합과 자유도의 분할
제곱합 등식
$${SS_T}{=}{SS_{Res}}{+}{SS_{Reg}}$$
자유도 등식
$$n-1=1+(n-2)$$
$Y$의 관측값들이 가지는 총변동을 나타내는 제곱합으로 이를 총제곱합(total sum of squares, $SS_T$)이라고 합니다. 이 $SS_T$는 자유도, $(n-1)$을 가지며 이 자유도로 나누면 $Y_{i}$ 값들의 표본분산이 되며 다음과 같습니다.
$${SS_T}=\sum\limits_{i=1}\limits^{n}(Y_{i}-\bar{Y})^2$$
잔차들의 제곱합으로 $Y$의 총변동 중 설명 안된 변동(unexplained variation)을 잔차들의 제곱합이라하며 이를 잔차제곱합(error sum of squares, $SS_{Res}$)이라 합니다. 이 제곱합의 계산을 위해서는 두 개의 모수인 회귀직선의기울기를 나타내는 회귀계수, $\beta_1$와 회귀직선의 절편인 회귀계수, $\beta_0$를 추정해야 합니다. 따라서 $SS_{Res}$는 $(n-2)$의 자유도를 가집니다. 그래서 잔차 표집의 표본분산인 $S_{Res}^2$을 구할 때 $(n-2)$로 나누어 줍니다. 잔차제곱합은 다음과 같습니다.
$${SS_{Res}}=\sum\limits_{i=1}\limits^{n}(Y_{i}-\hat{Y}_{i})^2$$
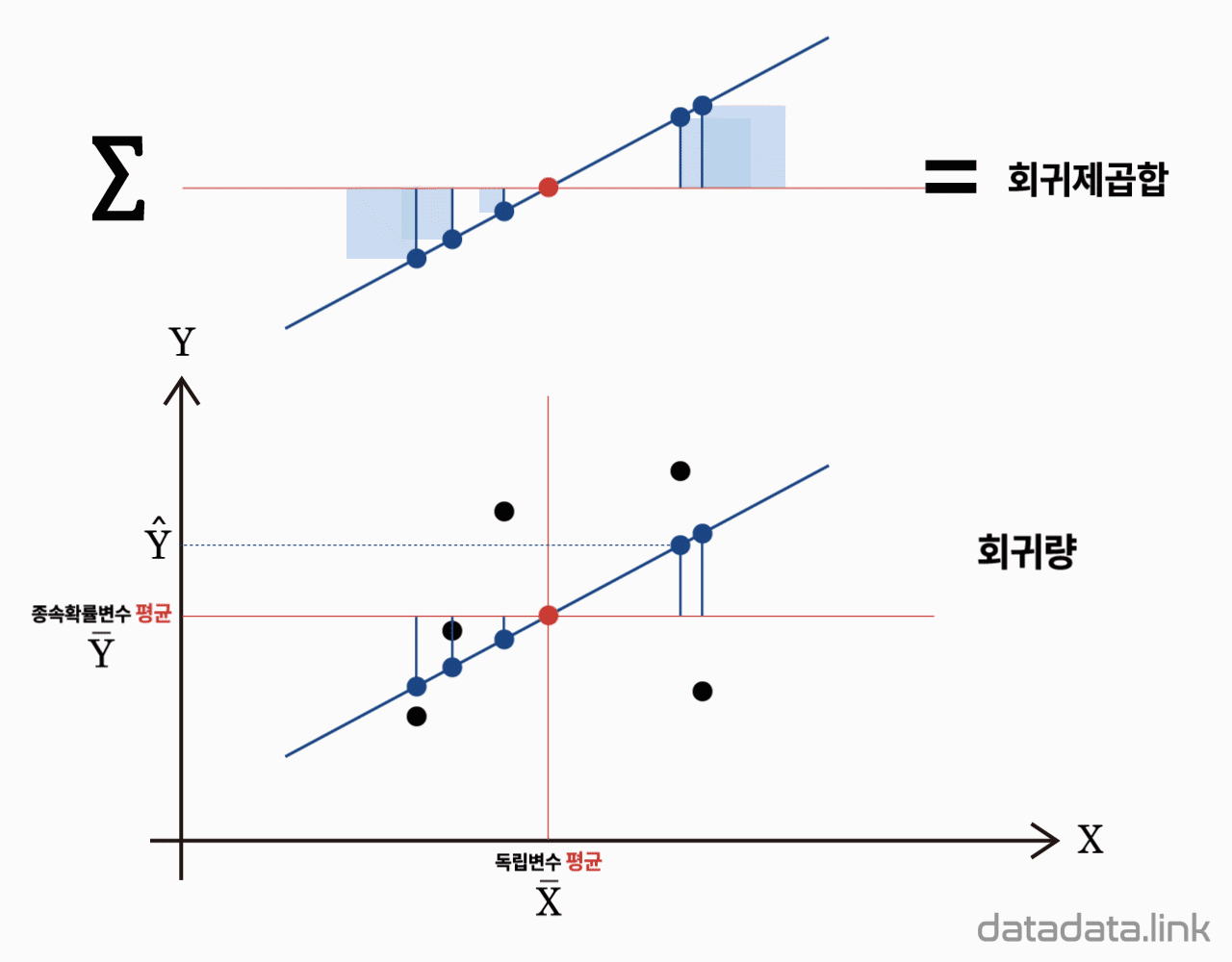
$Y$의 총변동 중 회귀식에 의해 설명된 변동(explained variation)을 회귀제곱합(regression sum of squares, $SS_{Reg}$)이라고 합니다. 이 회귀제곱합은 자유도 1을 가집니다. 즉, 두 집단(회귀직선상에 있는 집단과 회귀직선상에 없는 집단)의 표본 중에서 회귀직선이 정해지면 나머지 집단의 표본은 자동으로 정해지기 때문에 자유도가 1이 됩니다. 만일 추정된 회귀식이 모든 표본의 변동을 완전히 설명하고 있다면 (예를 들면, 모든 관측값들이 표본회귀직선 위에 있을 경우), 설명 안된 변동 $SS_{Res}$는 0이 됩니다. 따라서, 총제곱합 $SS_T$ 중에서 $SS_{Res}$가 차지하는 부분이 작으면, 또는 $SS_{Reg}$이 차지하는 부분이 크면 추정된 회귀모델의 적합도가 높다고 할 수 있습니다. 회귀제곱합은 다음과 같습니다.
$${SS_{Reg}}=\sum\limits_{i=1}\limits^{n}(\hat{Y}_{i}-\bar{Y})^2$$
총변동 $SS_T$ 중에서 설명된 변동 $SS_{Reg}$이 차지하는 비를 결정계수(coefficient of determination)라 합니다. 결정계수는 회귀직선의 적합도를 나타내며 다음과 같습니다.
$$R^2=\dfrac{SS_{Reg}}{SS_T}=\dfrac{SS_{Reg}}{SS_{Reg}+SS_{Res}}$$
여기서, $SS_{Reg}$는 회귀제곱합
$SS_{Res}$는 잔차제곱합
$SS_T$는 총제곱합
결정계수의 값은 항상 0 과 1 사이에 있습니다. 결정계수가 1에 가까울수록 표본의 데이터가 회귀직선 주위에 밀집되어 있어 추정된 회귀식이 관측값(데이터)를 잘 대표하고 있다고 할 수 있습니다.
Terminology
회귀분석(regression analysis)
통계에서 회귀분석(regression analysis)은 변수간의 관계를 추정하기 위한 통계적 과정입니다. 회귀분석은 종속변수(independent variables)와 하나 이상의 독립변수(dependent variable) 사이의 관계를 살펴보고자 할 때 여러 변수를 모델링하고 분석하는 다양한 기법을 가지고 있습니다. 구체적으로 회귀분석은 독립변수 중 하나가 변할 때 종속변수 (기준 변수)의 값이 변하는 반면 다른 독립변수는 고정되어 있는지를 이해하는 데 도움이 됩니다. 일반적으로, 회귀분석은 독립변수가 고정될 때 종속변수의 평균값, 또는 종속변수의 조건부기대치(conditional expectation)를 추정합니다.
일반적이지는 않지만 관심은 사분위수(quantile)나 위치매개변수(location parameter)에 있습니다. 여기서 위치매개변수는 독립변수가 주어진 종속변수의 조건부 분포를 보여줍니다.
모든 경우에 회귀함수(regression function)라 불리는 독립변수의 함수를 추정해야 합니다. 회귀분석에서, 확률분포(probability distribution)를 사용하여 회귀함수를 예측하면서 종속변수의 변화를 특정하는 것도 중요합니다. 확실한 접근법은 필수조건분석(NCA, Necessary Condition Analysis)입니다. 이 분석은 주어진 독립변수(중심선이 아닌 천장선)에서 종속변수의 평균보다는 최대값을 추정합니다. 이는 주어진 종속변수에서 어떤 독립변수값이 중분하지 않더라도 필요한 것이냐를 정하기 위함입니다.
회귀분석은 예측(prediction) 및 예견(forecasting)에 널리 사용되며, 그 사용은 기계학습(machine learning) 분야와 실질적으로 중복됩니다. 회귀분석은 독립변수 중 어떤 것이 종속변수와 관련되어 있는지 이해하고 어떤 관계가 있는지 탐구하기 위해 사용됩니다.
제한적인 환경에서는 회귀분석을 사용하여 독립변수와 종속변수 간의 인과 관계(causal relationships)를 추론 할 수 있습니다. 그러나 이것은 환상이나 잘못된 관계로 나타날 수 있으므로 주의가 필요합니다.
회귀분석을 수행하는 많은 방법이 개발되었습니다. 선형회귀(linear regression) 및 최소제곱(ordinary least squares)와 같은 친숙한 방법은 매개변수적(parametric)입니다. 그래서 회귀함수는 유한개의 모르는 매개변수들로 정해집니다. 여기서 매개변수들은 데이터로부터 추정됩니다.
비모수회귀(Nonparametric regression)는 회귀함수를 무한차원(infinite-dimensional) 함수로 규정하는 기술을 나타냅니다.
회귀분석 방법의 실행은 실제로 데이터생성과정(data generating process)과 사용되는 회귀분석 방법이 어떻게 관련이 있느냐 입니다. 데이터생성과정의 실제 형태는 일반적으로 알려져 있지 않기 때문에 회귀분석은 이 과정에 대해 어느 정도 가정을 수행합니다. 이러한 가정은 충분한 양의 데이터를 사용할 수 있는 경우는 검정할 수 있습니다.
예측을 위한 회귀모델은 가정이 적당히 위배되는 경우에는 최적으로 수행 할 수는 없지만 그래도 유용합니다. 그러나 많은 응용에서, 특히 작은 영향(effects)이나 관측데이터(observational data)에 근거한 인과관계(causality)의 문제로 회귀분석법은 오도된 결과를 줄 수 있습니다.
좁은 의미에서, 회귀는 연속 종속변수(반응변수)의 추정에 특별히 적합할 지도 모릅니다. 회귀는 분류에 사용되는 분류(classification)에 사용되는 불연속 반응변수(종속변수)에는 반대입니다. 연속 종속변수의 경우는 관련 문제와 구별하기 위해 보다 특별히 행렬 회귀(metric regression)라고 할 수 있습니다.
출처
Reference
본인의 Google 계정으로 구글시트를 복사
=COUNTA(B3:B22) : B3~B22 행의 범위에 있는 데이터의 개수
=COUNT(C3:C22) : C3 ~C22 행의 범위에 숫자 데이터의 개수