Learning DATALINK
로그인
구글시트
수집, 시각화, 설명
확률모델, 새 확률변수, 통계모델, 연구계획
모수추정, 모수비교
확률변수가정: 선형성, 등분산성, 독립성, 정규성
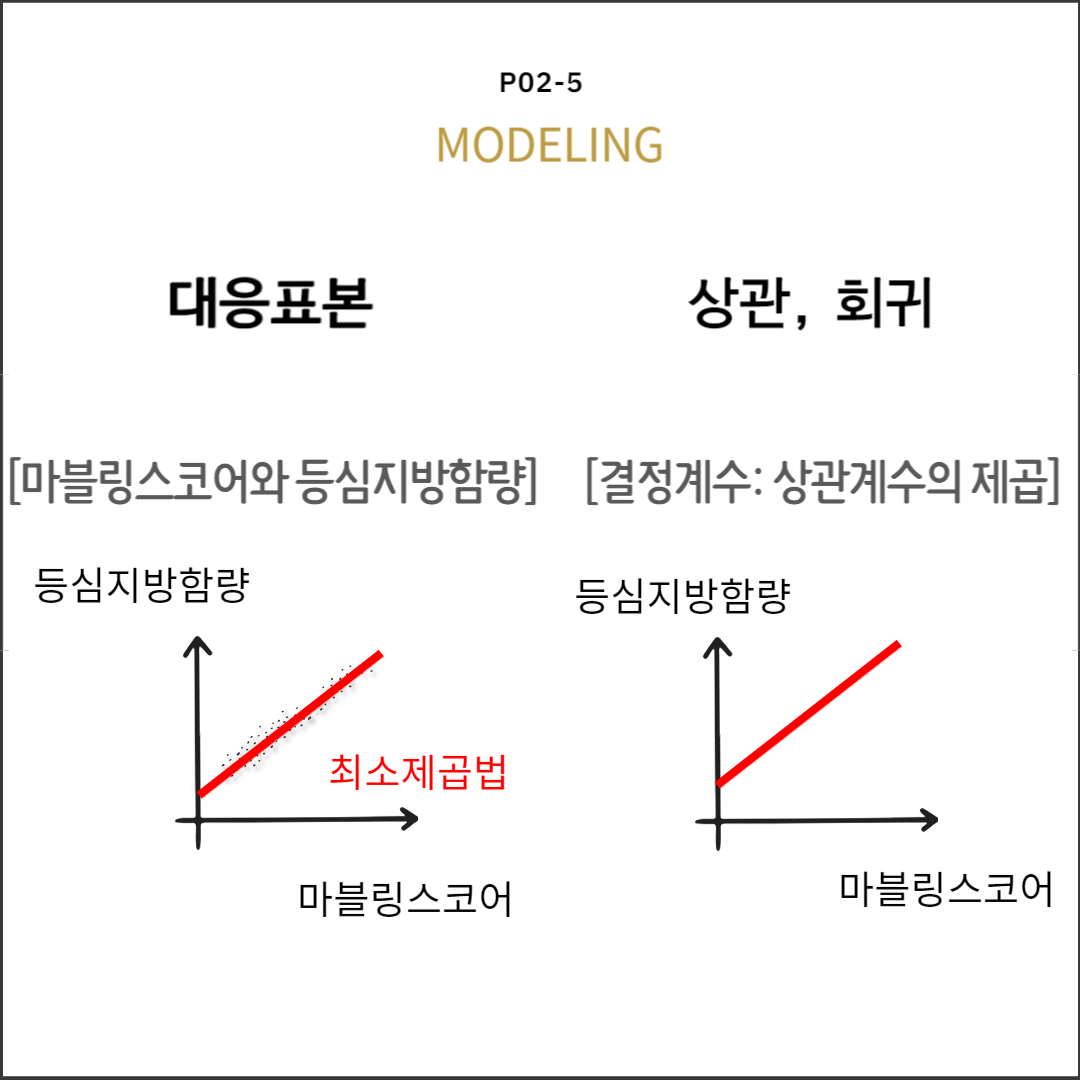
표집분포: 결정계수 중심극한정리
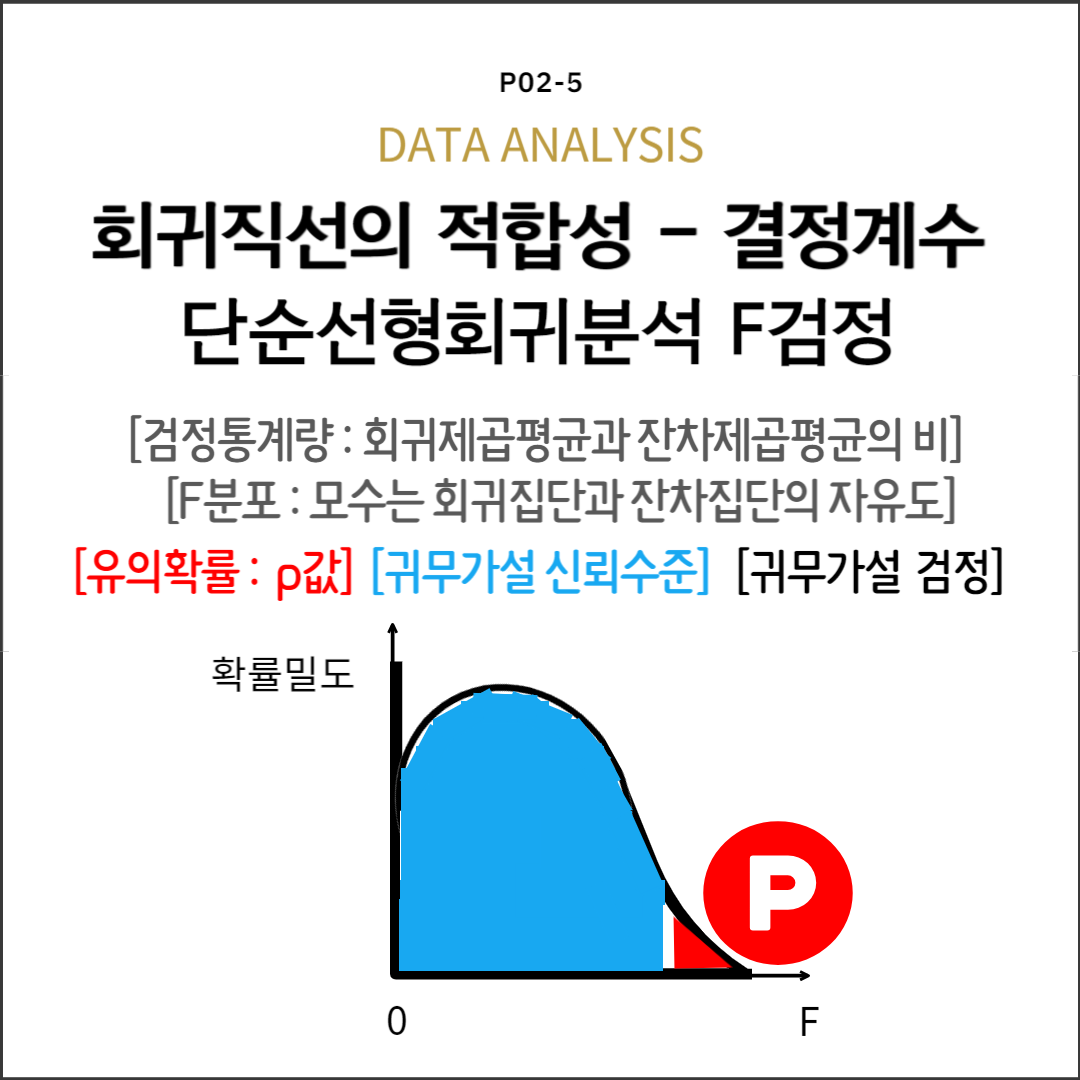
검정통계량: 표본결정계수와 표준오차의 비
가설검정: 유의확률과 유의수준을 비교
$$f(y \, ; \mu_Y, \sigma_Y^2)=\dfrac{1}{\sqrt{2\pi}\sigma_Y} \mathrm{exp} \left(-\dfrac{(y-\mu_Y)^2}{2\sigma_Y^2}\right)$$
여기서, $y$는 정규분포를 나타내는 확률변수, $Y$의 값(변량)
$\mu_Y$는 확률변수, $Y$의 기대값: 집단의 모평균
$\sigma_Y^2$는 확률변수, $Y$의 모분산: 집단의 모분산
$$\chi^2= Z_1^2 + Z_2^2 + \cdots = \sum\limits_{i=1}^{k}Z_{i}^2$$
여기서, $Z_i$는 표준정규분포 확률변수$k$는 자유도: 표준정규분포 확률변수 개수
$$f(x \, ; k)=\dfrac{1}{2^{\frac{k}{2}}\Gamma\left(\frac{k}{2}\right)}x^{\frac{k}{2}-1}e^{-\frac{x}{2}}$$
여기서, $x$는 카이제곱분포를 나타내는 확률변수의 값(변량)
$k$는 자유도: 확률변수제곱의 개수
$$F = \dfrac{\frac{\chi^2_1}{d_1}}{\frac{\chi^2_2}{d_2}}$$
여기서, $F$는 F분포를 나타내는 확률변수
$\chi^2_1$과 $\chi^2_2$는 카이제곱분포를 나타내는 확률변수
$d_1$과 $d_2$는 $\chi^2_1$과 $\chi^2_2$가 나타내는 카이제곱분포의 자유도
$$f(x; d_1, d_2) = \frac{\left(\dfrac{d_1}{d_2}\right)^{\frac{d_1}{2}} x^{\frac{d_1}{2} – 1} \left(1 + \frac{d_1}{d_2}x\right)^{-\frac{d_1 + d_2}{2}}}{B\left(\frac{d_1}{2}, \frac{d_2}{2}\right)}$$
여기서, $x$는 F분포를 나타내는 확률변수의 값(변량)
$d_1$과 $d_2$는 각각 분자와 분모의 자유도
$B(\,\,)$는 베타함수
$B(\frac{d_1}{2}, \frac{d_2}{2}) = \frac{\Gamma(\frac{d_1}{2}) \Gamma(\frac{d_2}{2})}{\Gamma(\frac{d_1}{2} + \frac{d_2}{2})}$
$\Gamma(\,\,)$는 감마함수
$$F=\dfrac{MS_{B}}{MS_{W}}=\dfrac{\dfrac{SS_{B}}{k-1}}{\dfrac{SS_{W}}{n-k}}$$
여기서, $MS_B$는 집단간분산
$MS_W$는 집단내분산
$SS_B$는 집단간변동
$SS_W$는 집단내변동
$k$는 집단수
$n$은 표본크기
$$F=\dfrac{MS_{Reg}}{MS_{Res}}=\dfrac{\dfrac{SS_{Reg}}{k-1}}{\dfrac{SS_{Res}}{n-k}}=(n-2)\dfrac{SS_{Reg}}{SS_{Res}}$$
여기서, $MS_{Reg}$는 회귀분산: 회귀집단의 분산
$MS_{Res}$는 잔차분산: 잔차집단내분산 $\because$ 회귀집단내분산=0
$SS_{Reg}$는 회귀변동
$SS_{Res}$는 잔차변동
$k$는 집단수: 회귀집단과 잔차집단 $\therefore k=2$
$$R^2=\dfrac{SS_{Reg}}{SS_T}=\dfrac{SS_{Reg}}{SS_{Reg}+SS_{Res}}$$
여기서, $SS_{Reg}$는 회귀제곱합
$SS_{Res}$는 잔차제곱합
$SS_T$는 총제곱합
$$\dfrac{SS_{Reg}}{SS_{Res}}=\dfrac{R^2}{1-R^2}$$
$$F=(n-2)\dfrac{R^2}{1-R^2}$$
여기서, $n$은 표본크기
$R^2$은 결정계수
$$R^2=r^2$$
$$F=(n-2)\dfrac{r^2}{1-r^2}$$
$r$은 표본피어슨상관계수