[DATA SCIENCE]
데이터사이언스 > 모델링 > 새로운 확률변수 > 확률변수의 합과 차이
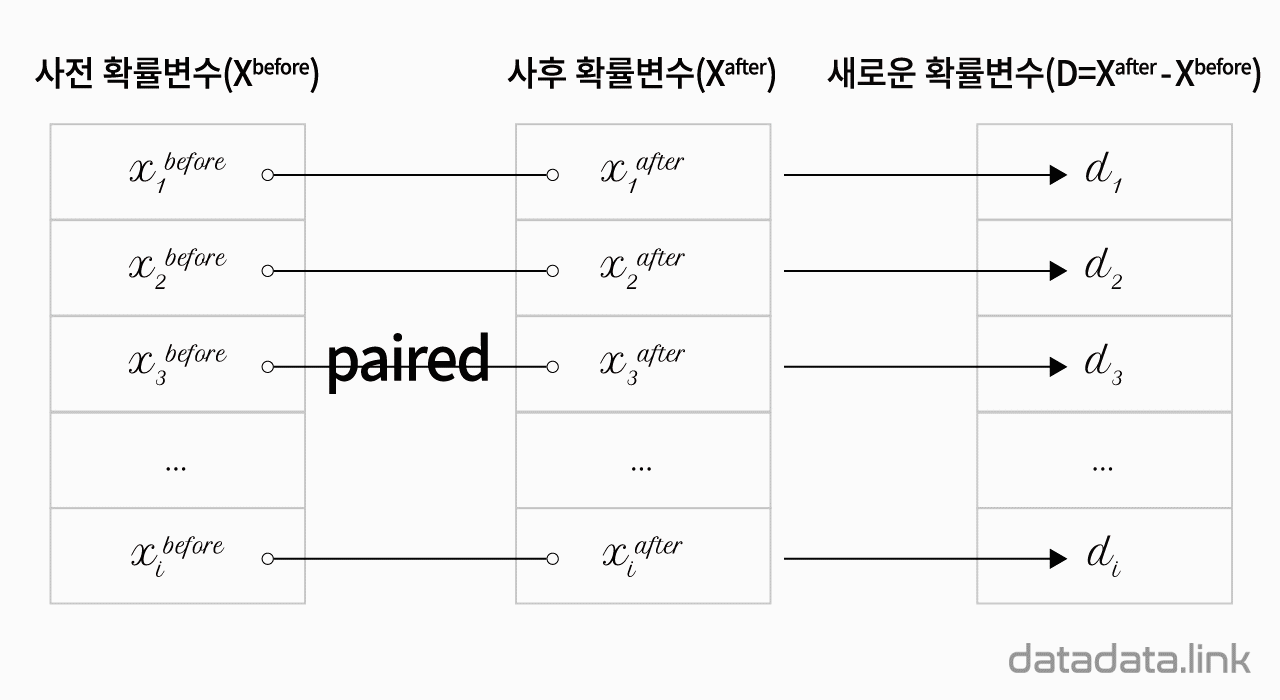
대응된 두 확률변수 차이
[Q&A]
- Q 모집단(population)과 집단(group, category)를 구분 – A 집단은 모집단의 부분집합, 모집단의 일부 속성을 상속, 집단의 속성을 모두 모은 것이 모집단, 집단과 모집단은 모두 iid 확률변수를 가지는 개체로 이루어짐.
- Q. 대응된 표본에서 두 모평균 차이의 기대값의 표현방법 – A. 새로운 확률변수의 표본평균의 추정량으로 표현.
- Q. 대응표본과 독립표본에서 두 확률변수의 차이의 기대값과 분산 – A. 대응표본과 독립표본의 분석에서 두 확률변수의 차이인 새로운 확률변수의 기대값은 같지만 분산은 같지 않고 부등식관계.
- Q. 대응표본을 이용한 모집단 추론과 독립표본을 이용한 모집단 추론의 차이 – A ‘대응표본을 이용한 모집단의 추론’은 대응표본을 하나의 모집단에서 추출한 단일 랜덤표본으로 간주하여 분석합니다. 이 점이 여러 모집단에서 추출한 여러 표본의 표본통계량으로 분석하는 ‘독립표본을 이용한 모집단의 추론’과 근본적으로 다름.
[Q&A]
모집단(population)과 집단(group, category)를 구분
집단은 모집단의 부분집합, 모집단의 일부 속성을 상속, 집단의 속성을 모두 모은 것이 모집단, 집단과 모집단은 모두 iid 확률변수를 가지는 개체로 이루어짐.
대응된 표본에서 두 모평균 차이의 기대값의 표현방법
새로운 확률변수의 표본평균의 추정량으로 표현
대응표본과 독립표본에서 두 확률변수의 차이의 기대값과 분산
대응표본과 독립표본의 분석에서 두 확률변수의 차이인 새로운 확률변수의 기대값은 같음. 대응표본에서는 두 측정 간의 연관성을 나타내는 공분산을 고려해야 하며, 독립표본에서는 각 표본이 서로 독립적임을 가정하므로 공분산은 나타나지 않음
대응표본을 이용한 모집단 추론과 독립표본을 이용한 모집단 추론의 차이
‘대응표본을 이용한 모집단의 추론’은 대응표본을 하나의 모집단에서 추출한 단일 랜덤표본으로 간주하여 분석. 이 점이 여러 모집단에서 추출한 여러 표본의 표본통계량으로 분석하는 ‘독립표본을 이용한 모집단의 추론’과 근본적으로 다름.
ARTICLE CONTENTS
데이터종류
0:17Data & Code
1:09The difference between two matched random variables
Author
박근철![]() , 양윤원
, 양윤원![]()
DocuHut Co. Ltd., Seoul, Republic of Korea
Citation
Park GC, Yang YW. Data Type. Data Science 2024;1:1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
대응된 두 확률변수의 차이를 이용해 새로운 확률변수를 생성하는 과정은 통계학에서 중요한 개념입니다. 이 접근법은 두 확률변수의 차이를 통해 정의됩니다. 이때, 새로운 확률변수의 값은 대응이 있는 두 관측값의 차이로 계산되며, 새로운 확률변수의 표본평균과 분산은 각각 두 모평균의 차이와 이 차이에 대한 추정량을 통해 계산됩니다. 이 방식은 대응표본에서 두 집단 간의 차이를 분석할 때 활용되며, 두 집단의 모평균 차이의 기대값을 새로운 확률변수의 표본평균으로 추정하게 됩니다. 이러한 방식으로 대응된 표본의 평균과 새로운 확률변수의 표본평균 표집 분산을 계산할 수 있으며, 이는 두 집단 간의 차이를 정량적으로 평가하는 데 중요한 도구입니다. 대응표본 분석은 두 표본이 서로 대응되어 있을 때 사용되며, 독립표본 분석과는 다른 접근법을 제공합니다.
Key Word
대응된 확률변수, 확률변수의 차이, 새로운 확률변수, 두 집단의 모평균 차이, 대응표본 분석, 독립표본 분석
대응된 두 확률변수의 차이
대응된 확률변수의 차이로 새로운 확률변수를 생성합니다.
대응된 두 확률변수의 차이는 확률변수이며 이 새로운 확률변수는 다음식으로 표현할 수 있습니다.
$$D_i = X_{2i} – X_{1i}$$
여기서, $i$는 $i$번째 대응됨을 나타내는 양의 정수
$i$번째 대응된 두 확률변수값 $x_{2i}$와 $x_{1i}$의 차이로 $i$번째 생성된 확률변수값 $d_{i}$은 다음 등식이 성립합니다.
$$d_i = x_{i2} – x_{i1}$$
여기서, $i$는 1부터 표본크기 $n$까지의 양의 정수
새로운 확률변수의 표본평균은 확률변수이며 다음식으로 표현할 수 있습니다.
$$\bar D_{i} = {\bar X}_{2i} – {\bar X}_{1i}$$
여기서, $i$는 1부터 표본크기 $n$까지의 양의 정수
새로운 확률변수($D_i$)의 모평균($\mu_{D_i}$)을 다음식으로 표현할 수 있습니다.
$$\mu_{D_i} = \mu_{X_{2i}} – \mu_{X_{1i}}$$
여기서, $i$는 $i$번째 대응됨을 나타내는 양의 정수
$\mu_{X_{1i}}$는 확률변수 $X_{1i}$의 모평균
$\mu_{X_{2i}}$는 확률변수 $X_{2i}$의 모평균
$D_i$의 분산은 다음식으로 표현할 수 있고 표본데이터(관측값 집합)로 추정할 수 있습니다.
$$\mathrm Var[D_{i}]=\sigma^2_{D_i}≈S^2_{D_i}$$
여기서, $\sigma^2_{D_i}$는 모분산
≈ 는 점추정(point estimation)
$S^2_{D_i}$는 표본분산이며 $i$는 1부터 표본크기 $n$까지의 양의 정수
새로운 확률변수($D_i$)의 표본평균($\bar D_i$)의 기대값
대응된 표본에서 두 모평균 차이의 기대값을 새로운 확률변수의 표본평균의 추정량으로 표현할 수 있습니다. 대응표본에서는 두 표본이 대응되어 있으므로 쌍을 이루는 두 관측값의 차이를 분석합니다. 즉 대응된 두 확률변수값의 차이의 집합인 {$d_1, d_2, \cdots, d_n$}을 하나의 모집단에서 추출한 단일 랜덤표본으로 간주하여 분석합니다. 이 점이 여러 모집단에서 추출한 여러 표본의 표본통계량으로 분석하는 ‘독립표본을 이용한 모집단에 대한 추론’과 근본적으로 다릅니다. 이 새로운 확률변수($\bar D_i$)의 기대값은 두 집단의 모평균의 차이와 같습니다. 대응표본과 독립표본의 분석에서 두 확률변수의 차이인 새로운 확률변수의 기대값은 같지만 분산은 같지 않습니다. 새로운 확률변수의 표본평균의 기대값은 다음식으로 표현할 수 있습니다.
$${\rm E}[\bar D_i] = \mu_{D_i} = \mu_{X_{2i}} – \mu_{X_{1i}} ≈ \bar X_{2i} – \bar X_{1i}= \dfrac{\sum\limits_{i=1}^n {X_{2i}}}{n}-\dfrac{\sum\limits_{i=1}^n {X_{1i}}}{n}=\dfrac{\sum\limits_{i=1}^n ({X_{2i}}-{X_{1i}})}{n}$$
여기서, $\mu_{D_i}$ 는 두 모집단의 대응된 원소의 차이로 생성된 새로운 확률변수의 모평균
≈ 는 점추정(point estimation)
$\mu_{X_{1i}}$, $\mu_{X_{2i}}$는 모평균
$\bar X_{1i}$, $\bar X_{2i}$는 표본평균
대응표본( $d_i$)의 평균($\bar D_i$)의 추정량은 다음식과 같습니다.
$$\bar {D_i}= \dfrac{\sum\limits_{i=1}^n {d_i}}{n}$$
여기서, $n$은 표본크기
새로운 확률변수($D_i$)의 표본평균 표집의 분산(${\rm Var}[\bar {D_i}]$)
대응된 두 확률변수의 차이로부터 유도된 새로운 확률변수($D_i$)의 표본평균($\bar D_i$) 의 표집의 분산(${\rm Var}[\bar D_i]$)은 다음식으로 표현됩니다.
$${\rm Var}[\bar D_i] = {\rm Var}[\bar d_i] = \dfrac{\sigma^2_{D_i}}{n}$$
여기서, $n$은 표본크기
새로운 확률변수 $D_i$의 모분산($\sigma^2_{D_i}$)의 점추정량인 표본분산($S^2_{D_i}$)은 다음과 같습니다.
$$S^2_{D_i} = \dfrac{\sum\limits_{i=1}^n {(d_{i}-\bar {d_i})^2}}{n-1}$$
여기서, $(n-1)$은 표본의 자유도
Terminology
확률변수
확률이론 및 통계에서 임의의 양, 임의의 변수, 즉 확률변수는 비공식적으로 값이 임의의 현상의 결과에 의존하는 변수로 설명됩니다. 확률변수에 대한 공식적인 수학적 설명은 확률이론의 주제입니다. 그 맥락에서, 확률변수는 결과가 일반적으로 실수인 확률공간에서 정의된 측정 가능한 함수로 이해할 수 있습니다.
확률변수의 가능한 값은 아직 수행되지 않은 실험의 가능한 결과 또는 이미 존재하는 값 불확실한 과거 실험의 가능한 결과인 경우를 나타내는 이미 존재하는 값으로 나타낼 수 있습니다 (예 : 부정확한 측정 또는 양자 불확실성으로 인해). 그들은 또한 개념적으로 “객관적”무작위 과정의 결과 또는 양에 대한 불완전한 지식으로 인한 “주관적인”무작위성”을 나타낼 수 있습니다. 확률변수의 잠재 가치에 할당된 확률의 의미는 확률 이론 자체의 일부가 아니며 확률의 해석에 대한 철학적 주장과 관련이 있습니다. 수학은 사용되는 특정 해석과 상관없이 동일하게 작동합니다.
함수로서 확률변수는 측정 가능해야 하며 확률은 잠재가치 집합으로 표현할 수 있습니다. 결과는 예측할 수 없는 몇 가지 물리적 변수에 달려 있을 수 있습니다. 예를 들어, 공정한 동전 던지기의 경우, 앞면 또는 뒷면의 최종 결과는 불확실한 동전의 물리적 조건에 달려 있습니다. 관찰되는 결과는 확실하지 않습니다. 동전의 표면에 균열이 생길 수 있지만 이러한 가능성은 고려 대상에서 제외됩니다.
확률변수의 존재 지역은 표본공간이며 임의의 현상의 가능한 결과의 집합으로 해석됩니다. 예를 들어, 동전 던지기의 경우 두 가지 가능한 결과, 즉 앞면 또는 뒷면이 그러합니다.
확률변수는 확률분포를 가지며, 확률분포는 확률변수의 확률값을 지정합니다. 무작위 변수는 이산형일 수 있습니다. 즉, 임의의 변수의 확률분포의 확률 질량함수 특성이 부여된 유한한 값 또는 계산 가능한 값에서 하나를 취합니다. 또는 임의의 변수의 확률분포의 특징 인 확률밀도함수를 통해 간격 또는 연속된간격에서 임의의 수치 값을 취하는 연속 또는 두 유형의 혼합물 일 수 있습니다.
동일한 확률분포를 갖는 두 개의 확률 변수는 다른 확률 변수와의 관련성 또는 독립성 측면에서 다를 수 있습니다. 무작위 변수의 실현, 즉 변수의 확률분포 함수에 따라 무작위로 값을 선택한 결과를 무작위 변수라고 합니다.
출처
확률분포
확률이론 및 통계에서 확률분포는 실험에서 가능하고 서로 다른 모든 결과의 출현 확률을 제공하는 수학적 기능입니다. 보다 기술적인 측면에서, 확률분포는 사건의 확률의 관점에서 임의의 현상에 대한 기술입다. 예를 들어, 확률 변수 $X$가 동전 던지기( “실험”) 결과를 나타내는 데 사용되면 $X$의 확률 분포는 $X$ = 윗면의 경우 0.5, $X$ = 아래면의 경우 0.5를 취합니다( 동전은 공정). 임의의 현상의 예에는 실험이나 조사의 결과가 포함될 수 있습니다.
확률분포는 관찰되는 임의의 현상의 모든 가능한 결과 집합인 기본 표본공간(sample space)의 관점에서 지정됩니다. 표본공간은 실수 집합 또는 벡터 집합일 수도 있고 비 숫자 값 목록일 수도 있습니다. 예를 들어, 동전 뒤집기의 샘플 공간은 {머리, 꼬리}입니다. 확률 분포는 일반적으로 두 가지로 나뉩니다. 이산 확률분포 (동전 던지기 나 주사위와 같이 가능한 결과 집합이 불연속인 시나리오에 적용 가능)는 확률질량함수라고하는 결과의 확률에 대한 개별 목록으로 표시할 수 있습니다. 반면, 연속확률분포 (주어진 날의 온도와 같이 연속적인 범위 (예 : 실수)의 값을 취할 수 있는 시나리오에 적용 가능)는 일반적으로 확률 밀도함수 (임의의 개별 결과가 실제로는 0인 확률)로 표현할 수 있습니다. 정규 분포는 일반적으로 자주 나타나는 연속확률분포입니다. 지속적인 시간에 정의 된 확률론적 과정과 관련된 복잡한 실험은 더 일반적인 확률측정법의 사용을 요구할 수 있습니다.
표본공간이 1차원인 확률분포 (예 : 실수, 레이블 목록, 정렬된 레이블 또는 이진수)는 단 변수이라고 불리우는 반면 표본공간이 2차원 이상의 벡터 공간 인 분포를 다 변수라고합니다. 단일 변수(변량) 분포는 다양한 대체 값을 취하는 단일 확률변수의 확률을 제공합니다. 다 변수 분포 (합동확률분포)는 다양한 값의 조합을 취하는 임의의 벡터 (두 개 이상의 임의변수를 원소로 가짐)의 확률을 제공합니다. 중요하고 공통적으로 발생하는 단 변량 확률분포에는 이항분포, 초기 하분포 및 정규분포가 포함됩니다. 다 변수 정규 분포는 일반적으로 발생하는 다 변수 분포입니다.
출처처
확률밀도함수
확률에서 확률밀도함수(PDF) 또는 연속확률변수의 밀도는 표본공간의 임의의 표본(또는 점)의 확률변수의 값이 같다면 같은 확률을 가진다는 것입니다. 다른 말로 하면, 임의의 연속확률변수에 대한 확률값은 0이지만 두 개의 서로 다른 확률변수 값에서 PDF의 값을 사용하여 유추할 수는 있습니다. PDF는 임의의 확률변수에서의 확률값을 취하는 것보다는 특정 확률변수 범위 내에서 임의의 확률변수가 있을 확률을 나타내는데 사용됩니다. 확률은 확률변수의 범위에 대한 PDF의 적분값으로 주어집니다. 확률밀도함수는 모든 곳에서 음수가 아니며 전체 확률변수범위에 대한 적분은 1이 됩니다.
“확률분포함수”와 “확률함수”라는 용어는 때로는 확률밀도함수를 의미하기도 하지만 이 용어는 표준이 아닙니다. 한편, 확률질량함수(PMF)는 이산확률변수 (불연속 확률변수)에서 사용되는 반면확률밀도함수(PDF)는 연속확률변수에서 사용됩니다.
출처처
표준오차
통계에서 표준오차(standard of error)은 일반적으로 모수(매개변수, parameter)의 추정치입니다. 표준오차는 표집 분포의 표준편차 또는 모표준편차의 추정치입니다. 모수 또는 통계량이 평균인 경우는 평균의 표준오차(standard error of mean)라고 합니다.
집단의 표본평균 분포는 반복적으로 표본을 추출하고 표본평균값을 기록함으로써 생성됩니다. 이것은 다른 확률분포를 형성하며,이 분포는 고유한 평균과 분산을 갖습니다. 수학적으로 얻은 표본 분포의 분산은 집단의 분산을 표본크기로 나눈 값과 같습니다. 이는 표본크기가 증가함에 따라 표본평균이 집단의 평균에 더 밀접하게 밀집되기 때문입니다. 따라서 표준오차와 표준편차 사이의 관계는 주어진 표본 크기에 대해 표준오차가 표준편차를 표본크기의 제곱근으로 나눈 것과 같습니다. 즉, 평균의 표준오차는 집단의 평균을 중심으로 주위에 분포하는 표본평균의 분산의 척도입니다.
회귀분석에서 “표준오차”라는 용어는 특정 회귀계수의 신뢰구간에서 사용되며 카이제곱 통계량의 제곱근을 나타냅니다.
출처처
Reference
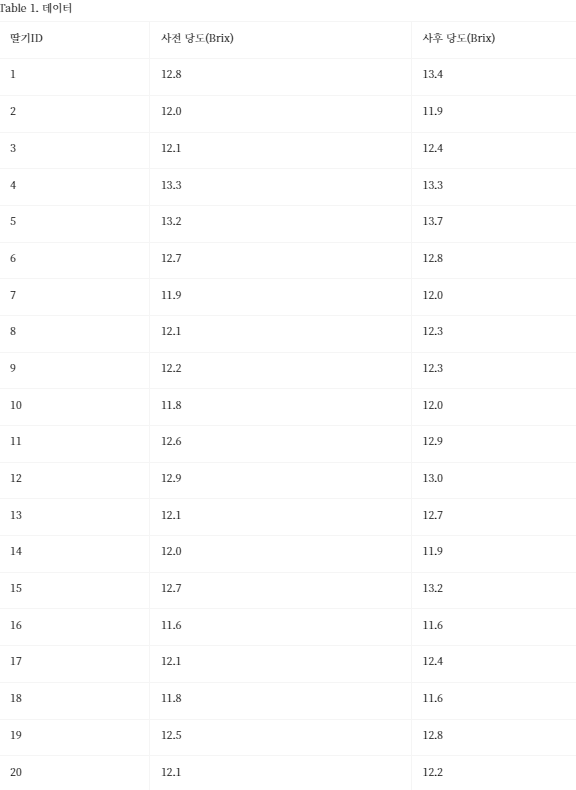
본인의 Google 계정으로 구글시트를 복사
=AVERAGE(B3:B38) : 평균
=VARP(B3:B38) : 분산. 모분산
=STDEV.P(B3:B38) : 표준편차. 모표준편차