[DATA SCIENCE]
데이터사이언스 > 모델링 > 확률모델 > 확률이론
확률변수


[Q&A]
- 딸기의 가치는 당도인가?
- 저온숙성은 딸기의 당도를 향상시키는가?
- 당도 측정도구에 적용된 척도는?
- 대응표본과 독립표본은 무엇이 다른가?
- 대응표본과 독립표본에서 새로운 확률변수를 확률변수값의 차이라고 할 때 어느 표본의 분산이 더 큰가?
- 차이평균의 귀무가설과 원점의 관계는?
- 표준편차는 단위가 될 수 있는가?
- t검정?
[Q&A]
보드게임을 변수로 모델링하면 변수값은
보드게임을 이분형변수(binomial variable)로 모델링할 수 있습니다, 보드게임은 “안한다”. “한다”라는 이분형 설명변수값을 가집니다.
수학적 창의력을 확률변수로 모델링 가능한가
유전적으로 결정된다면 확률변수로 볼 수 있습니다. 단, 나이에 따라 평균이 이동하는 것으로 모델링합니다.
초등학생의 수학적 창의력은 중심경향성을 가지는 확률변수인가
중심경향성을 가지는 확률변수입니다. 확률변수의 확률분포는 나이에 따라 중심의 위치값(대표값)이 증가하다가 하락한다고 알려져 있습니다. 확률분포의 분포정도(분포값)는 피험자의 태도와 관측환경에 따라 변한다고 알려져 있습니다.
새로운 확률변수는 무엇
초등학생의 보드게임 사전과 사후의 수학적 창의력 점수 차이입니다.
귀무가설은 기준을 생성하는가
절대 0이 없는 간격척도로 구한 데이터를 비교할 수 있게 해줍니다.
차이평균의 귀무가설과 원점의 관계는
귀무가설에서의 “0”은 두 모집단의 평균 차이가 없음을 나타내며, 이는 통계적으로 “원점” 또는 “기준점”으로 간주합니다.
대응표본과 독립표본에서 새로운 확률변수를 확률변수값의 차이라고 할 때 어느 표본의 분산이 더 큰가
일반적으로 독립표본에서의 새로운 확률변수의 분산이 대응표본에서의 새로운 확률변수의 분산보다 더 크다고 할 수 있습니다. 이는 독립표본의 경우 두 모집단의 변동성이 모두 분산에 기여하기 때문입니다.
표준편차는 단위가 될 수 있는가
표준편차의 단위는 데이터의 원 단위를 유지하기 때문에, 그것을 데이터 집합의 변동성을 나타내는 ‘단위’로 사용할 수 있습니다. 결론적으로, 표준편차를 단위로 사용하는 것은 엄밀히 말하면 정확하지 않지만, 특정 상황에서는 유용하게 활용될 수 있습니다. 사용 전에 주의 사항을 숙지하고, 필요에 따라 다른 방법을 함께 사용하는 것이 바람직합니다.
대응표본과 독립표본은 무엇이 다른가
독립표본은 독립된 두개 이상의 범주를 가집니다. 대응표본은 개체로 연결되어 있으며 같은 시간이나 공간의 이동으로 같은 개체의 속성변동을 반영합니다.
ARTICLE CONTENTS
Random variable
Author
박근철![]() , 양윤원
, 양윤원![]()
DocuHut Co. Ltd., Seoul, Republic of Korea
Citation
Park GC, Yang YW. Data Type. Data Science 2024;1:1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
Key Word
확률변수, 범주형, 이산형, 연속형
확률변수의 예
확률변수의 이름을 “로또복권의 등수”라 하고 모든 가능한 확률변수값을 1등, 2등, 3등, 4등, 5등 그리고 꽝으로 한다면 “로또복권의 등수”는 범주형 확률변수입니다. 따라서 6개의 확률변수값에 확률이 대응됩니다. 로또복권의 한 회차의 판매를 마감하면 각 등수에 대응되는 확률도 규정된 수식에 의해 계산됩니다.
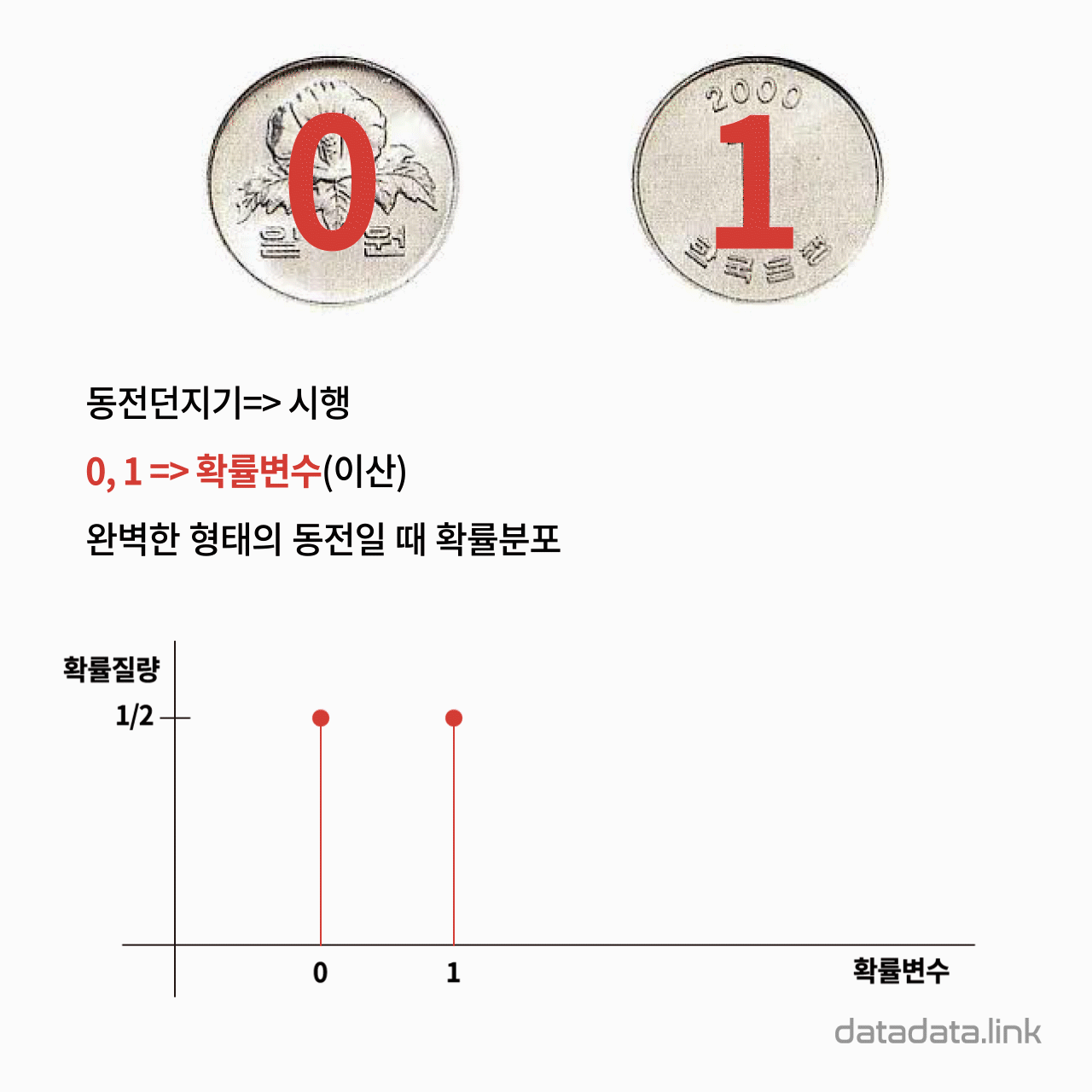
간단한 예로 동전던지기를 한 후 나온 윗면은 범주형 확률변수라고 할 수 있습니다. 만일, 0과 1을 써 놓은 동전은 확률변수값으로 0과 1 두 개를 가지게 되고 동전던지기를 한 후 나온 윗면은 이산형 확률변수가 됩니다. 그리고 완벽하게 두 면이 대칭된 동전이라면 한 개의 동전을 던져서 나온 확률변수값은 0과 1 두 개이고 확률변수값에 대응되는 확률은 각각 1/2로 같습니다. 여기서 확률(probability)이 있다는 것은 사건(event)이 있다는 것을 전제합니다. 즉, 동전을 던져서 윗면의 숫자를 관측한다는 시행(trial)을 해야 사건(event)을 정의할 수 있습니다. 정해진 시행에 나올 수 있는 모든 사건을 표본공간(sample space)이라고 합니다. 표본공간을 이루는 사건(event)을 기저사건(elementary event)이라고 합니다. 동전던기기라는 시행에서는 “0이 나오는 사건”과 “1이 나오는 사건”이 기저사건이 됩니다. 그리고 “아무것도 안나오는 사건”은 확률이 0인 사건이고 “0 또는 1이 나오는 사건”은 확률이 1인 사건입니다. 기저사건이 됩니다. 기저사건와 기저사건의 가능한 모든 합사건을 사건(event)이라 하며 모든 가능한 사건의 집합을 사건공간(event space)이라고 합니다. 동전의 한 면이 나올 확률을 일반화하여 $p$라고 하면 다른 한면의 확률은 $(1-p)$가 됩니다. 이런 경우를 특별히 베르누이 시행(Bernoulli try) 또는 베르누이 프로세스(Bernoulli process)라고 합니다.
12면 주사위는 기저사건이 12개입니다. 즉, 확률변수값이 12개입니다. 여기서도 주사위를 던진다는 시행(trial)이 전제되어야 사건(event)이 발생하고 확률이 존재합니다.
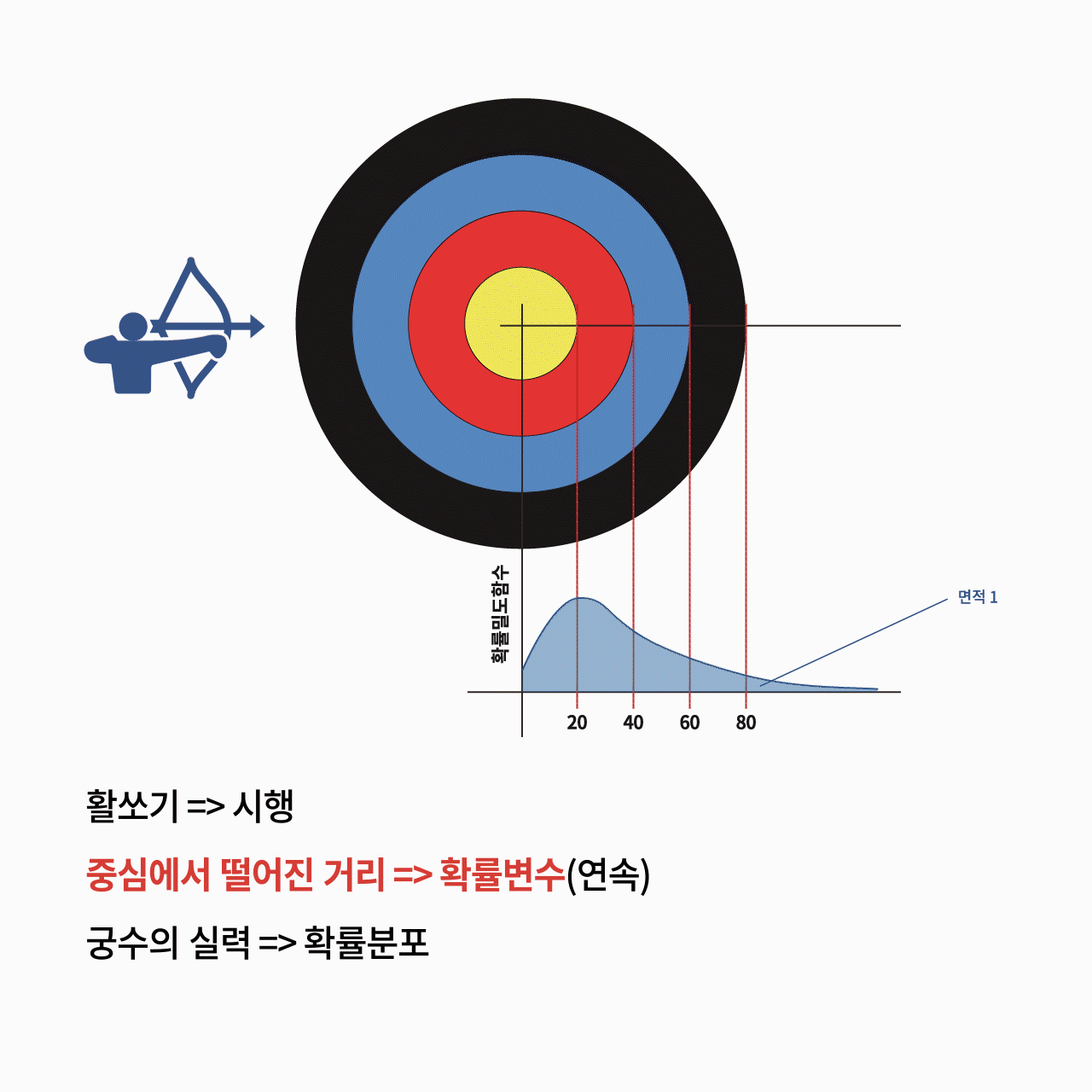
궁수가 과녁에 화살을 쏘는 행위를 할 때 궁수가 쏜 화살은 과녁의 나누어진 면적에 들어가거나 과녁의 중심에서 떨어진 거리를 나타낼 수 있습니다. 이 때 궁수의 실력을 확률변수로 표현할 수 있습니다. 궁수의 점수는 궁수의 실력이고 확률변수로 모델링할 수 있습니다. 이렇게 관측된 확률변수값을 데이터라고도 합니다. 궁수의 데이터가 많을 수록 궁수의 실력을 보다 정확히 말할 수 있습니다. 궁수의 점수의 확률분포는 궁수의 실력을 반영합니다. 궁수의 점수의 기대값이 높다고 하더라도 그 궁수가 활쏘기 대회에서 우승한다고 단언할 수는 없습니다. 확률을 붙여서 이야기 하는 것이 최선의 예측입니다. 만일 활쏘기 횟수가 적은 대회라면 더더욱 우승을 예측하기는 어려울 수 있습니다.
원형표적(target)은 총기가 만든 탄착군의 원의 면적으로 총기의 성능을 확률로 잘 설명할 수 있는 예입니다. 그래서 확률을 영어로 probability(가능성)뿐만아니라 stochastic(표적)으로도 표현합니다.
범주형 확률변수의 확률변수값의 예를 보면 다음과 같습니다.
– 동전의 확률변수값 : 앞면, 뒷면
– 6면 주사위의 확률변수값 : 1면, 2면, 3면, 4면, 5면, 6면
– 12면 주사위의 확률변수값 : 1면, 2면, 3면, 4면, 5면, 6면, 7면, 8면, 9면, 10면, 11면, 12면
– 과녁의 확률변수값 : 노랑, 빨강, 파랑, 검정
범주형 확률변수의 확률변수값은 질적속성을 나타내므로 질적 확률변수라고도 합니다. 이에 반해 확률변수값이 양적인 수치를 가지는 확률변수를 양적 확률변수라고 합니다. 양적 확률변수를 수치형 확률변수라고도 합니다. 양적 확률변수는 다시 이산형 확률변수와 연속형 확률변수로 나누어 집니다.
변수와 상수 그리고 확률변수
변수(變數, variable)
변수는 정해지지 않아 변하는 수 또는 변하는 것을 의미합니다. 변수는 변수명과 변수값으로 구성되며 변수명은 수(數)를 대신하는 대수(代數)를 표현하는 경우, 보통 $x, \, y, \, z$와 같이 뒤 쪽의 영문 소문자를 이용해서 표현합니다. 변수값은 자연수, 정수, 실수, 복소수 등의 수체계를 이루는 수(number)나 문자(character), 또는 수와 문자의 결합 등 다양한 형태를 가집니다. 변수값의 속성이 수치를 나타내는 경우, 이때의 변수값을 변량(variate)이라고 합니다. 정리하면, 변량은 수치로 실현되는 변수값을 의미합니다. 변량의 실현값은 간격척도나 비례척도가 적용된 관측도구로 측정된 양적 데이터입니다.
상수(constant)
상수는 항상 일정하여 변하지 않는 값 또는 변하지 않는 것을 의미합니다. 상수는 상수명과 정해진 수인 상수값으로 구성됩니다. 수학적 상수의 대표적인 예로는 원주율($\pi, 3.14159\cdots$)과 자연상수($e, 2.71828\cdots$)가 있고 없음과 있음을 나타내는 0과 1이 있습니다. 물리적 상수의 대표적인 예로는 광속(${\rm C}, \text{약}2.998\times 10^8 {\rm m/s}$)과 플랑그상수(${\rm h}, \text{약}6.626\times 10^{-28} {\rm Js}$) 등이 있습니다.
확률변수(random variable)
확률변수는 변수의 의미에 더하여 변수값이 확률을 가지는 변수입니다. 범주형이나 이산형 변수의 경우 변수값은 확률질량을 가지며 연속형 확률변수의 경우는 변수값에서 확률질량은 존재하지 않지만 확률밀도는 존재합니다. 확률변수는 변수이지만 특정 실험이나 관측을 통해 확률변수가 구체적인 값을 가지게 되면 상수처럼 다루어집니다. 예를 들어, 동전을 실제로 던져서 앞면이 나왔다면, 그 순간 확률변수는 ‘앞면’이라는 구체적인 값으로 고정됩니다. 확률변수에서 확률이 표현되는 변수값의 집합을 지지집합(support)이라고 부릅니다. 그리고 확률변수는 고유한 확률분포를 가집니다. 확률변수를 무작위변수(random variable)이라고 부르는 이유는 무작위로 변수값이 정해지면 고유의 확률분포가 나타나기 때문입니다. 같은 이유로 변수는 확률분포가 정해지지 않은 확률변수라고 할 수 있습니다.
확률변수의 성질
확률변수(random variable)는 말 그대로 확률을 가지는 변수입니다. 변수이기 때문에 어떤 값을 가질지는 모르지만 변수값에 따라 나올 가능성, 즉 확률(probability)이 정해져 있는 변수를 확률변수라고 합니다. 예를 들어 로또복권은 등수에 따라서 각각 다른 확률을 가지게 됩니다. 따라서 등수는 확률변수입니다. 확률변수를 표현하려면 확률변수명을 정하고 확률변수값에서의 확률분포를 정합니다.
동전던지기라는 시행으로 생성된 표본공간은 앞면과 뒷면입니다. 동전을 던져서 나온 윗면은 범주형 확률변수명이고 확률변수값은 앞면과 뒷면입니다. 따라서 척도로는 앞면과 뒷면이라는 명목을 가지는 명목척도가 사용됩니다. 주사위도 마찬가지로 6면을 1에서 6까지의 숫자로 표시하였을 때 “주사위 던지기”라는 시행에서 표본공간은 1, 2, 3, 4, 5, 6의 숫자이며 이는 바로 확률변수값으로 사용할 수 있습니다. 그리고 이 확률변수는 수치형(양적 데이터) 중에서 연속형이 아닌 이산형 확률변수입니다. 그리고 척도로는 수식계산이 가능한 간격척도가 사용됩니다.
확률변수를 정리하면 다음과 같습니다.
– 확률을 가지는 변수 : 특별히, 연속형 확률변수의 경우는 구간이 주어져야 확률을 가짐. 즉, 점에서의 확률은 0
– 시행(Trial)을 해서 어떤 사건이 나타났는지 보고 값이 정해지는 변수
– 고유의 확률분포를 가지는 변수이며 따라서 시행을 무한번 반복하여 나타난 시행결과들의 평균을 구하면 어떤 값, 즉 기대값에 수렴하는 변수
확률변수(random variable, stochastic variable, 確率變數)는 알파벳 대문자로 표기합니다. 아래 첨자로 확률변수를 구분하기도 합니다.
$$X, \, Y, \, Z$$
$$X_1, \, X_2, \, X_3$$
한 확률변수의 값(Value of random variable)은 확률변수에서 사용한 알파벳의 소문자를 사용합니다. 그리고 구분자는 아래첨자를 사용합니다.
$$x_1, x_2, x_3, \cdots $$
$$x_{11}, x_{12}, x_{13}, \cdots$$
확률변수와 표본평균의 중심경향성
확률변수가 나타내는 확률분포가 중심경향성을 가진다면 그 확률변수는 상수와 변수의 성질로 분리하여 생각할 수 있습니다. 중심경향성이 클수록 개념적으로 그 중심이 나타내는 상수에 가깝다고 할 수 있습니다. 반대 개념으로 골고루 퍼져있으면 변수의 성질을 더 잘 나타낸다고 할 수 있으며 가장 균등하게 퍼진 상태를 엔트로피(무질서도)가 가장 높은 상태라고 표현합니다.
모집단에서 표본을 추출할 때 표본평균을 확률변수로 모델링합니다. 이 때 표본평균은 모집단 평균을 중심으로 하는 확률분포를 보이며 중심경향성을 가진다고 볼 수 있습니다. 표본평균의 상수적인 성질은 합성함수(함수의 함수)로 모델링하여 새로운 확률변수를 생성합니다. 표본평균이 나타내는 중심경향성은 중심극한정리로 정립됩니다.
변수와 확률변수의 유형
범주형(categorical)
범주형 변수의 변수값은 원소의 수가 유한한 집합인 유한집합으로 표현됩니다. 범주형 변수의 변수값은 수치가 아닌 기호나 언어로 표현하며 기호나 언어는 순서를 가질 수도 있습니다. 범주형 변수의 변수값은 명목척도나 순서척도를 적용한 관측도구에 의해서 실현되는 값입니다. 범주형 확률변수는 범주형 변수와 마찬가지로 표현되나 확률이 있는 변수값만이 확률변수값이 됩니다. 범주형 확률변수는 각 변수값에서의 확률이 존재합니다. 그리고 이 확률은 0에서 1사이의 양(크기)으로 표현할 수 있기 때문에 “확률질량”이라고 표현합니다. 따라서 범주주형 확률분포는 확률질량함수(probability mass function, PMF)로 표현할 수 있습니다.
– 범주형 변수의 예 : 동전
동전을 바닥에 던져 관측하는 경우에는 가능한 변수값을 다음과 같은 집합으로 표현할 수 있습니다. 이 집합을 표본공간(sample space)이라고 합니다. 이 집합의 각각의 원소는 확률질량을 가질 수 있는 데 모든 확률질량의 합은 1이 됩니다.
$$\{\text{보이는 면, 안 보이는 면}\}$$
동전의 두 면에 기호를 적고 면에 적혀 있는 기호를 범주형 변수값으로 할 수 있습니다.
$$\{\text{앞 면, 뒷 면}\}$$
$$\{\text{H, T}\}$$
– 범주형 변수의 예 : 육각주사위
육각주사위에 기호를 적고 바닥에 던져 윗면에 적혀 있는 기호를 변수값으로 할 수 있습니다. 육각주사위가 정육면체를 가진다면 각 원소는 같은 확률을 가진다고 가정할 수 있어서 확률변수라고 할 수 있으나 현실에서 특정한 육각주사위의 확률분포는 실험 조건을 정하고 확률실험을 반복하여 통계적 확률분포를 구해야 합니다.
$$\{\text{1면, 2면, 3면, 4면, 5면, 6면}\}$$
$$\{\text{A, B, C, D, E, F}\}$$
– 명목형 변수의 예 : 문항
설문의 문항에 대한 답을 범주형 변수값으로 할 수 있습니다.
$$\{\text{싫다, 좋다}\}$$
$$\{\text{동의하지 않는다, 동의한다}\}$$
$$\{\text{매우동의하지 않는다, 동의하지 않는다, 중간이다, 동의한다, 매우 동의한다}\}$$
이산형(discrete)
이산형 변수는 범주형 변수의 성질을 가지고 변수값은 수치입니다. 이산형 변수의 변수값은 수체계로 표현됩니다. 이산형 변수의 변수값은 유한집합 또는 셀 수 있는 무한집합으로 표현됩니다. 이산형 확률변수는 이산형 변수와 마찬가지로 표현되나 확률이 있는 변수값만이 이산형 확률변수가 됩니다. 그리고 확률을 범주형 확률변수와 마찬가지로 확률질량으로 표현합니다. 이산형 확률변수는 각 변수값에서의 확률은 존재하지만 연속적이지 않으므로 확률의 변화율은 존재하지 않습니다. 따라서 이산형 확률분포는 확률질량함수(probability mass function, PMF)로 표현할 수 있습니다.
– 이산형 변수의 예 : 동전과 수행
동전의 두 면에 수치를 적고 수치만큼의 간격을 이동하는 것과 같은 행위를 수행한다면 이산형 변수가 됩니다.
$$\{1, 2\}$$
$$\{-1, 0, 1\}$$
– 이산형 변수의 예 : 육각주사위와 수행
육각주사위의 각 면에 수치를 적고 시행결과에 따라 칸을 이동하는 게임을 하는 경우
$$\{\text{1, 2, 3, 4, 5, 6}\}$$
$$\{\text{1, 10, 100, 1,000, 10,000, 100,000}\}$$
이산형 변수에 적용하는 수체계
연속형(continuous)
연속형 변수의 변수값은 셀 수 없는 무한집합으로 표현됩니다. 연속형 변수의 변수값은 수치이며 수체계 중에서 실수(real number)나 복소수(complex number)로 표현됩니다. 연속형 확률변수는 연속형 변수의 성질을 가지며 확률변수값이 아닌 확률변수의 구간에서 확률을 가집니다. 연속형 확률변수는 각 변수값에서의 확률은 0이지만 확률의 변화율은 존재하며 이를 “확률밀도”라고 부릅니다. 따라서 연속형 확률분포는 확률밀도함수(probability density function, PDF)로 표현할 수 있습니다.
– 연속형 변수의 예 : 수은온도계
물의 어는 온도에서의 수은의 부피를 0으로 하고 기화하는 온도에서의 부피를 100으로 할 때 온도에 따라 나타나는 부피는 연속형 변수입니다.
$$\{ \text{C} \mid -40 \lt x \lt 80 \}$$
– 연속형 확률변수의 예 : 태양빛의 파장
태양에서 방사되는 빛의 파장을 오랜 기간 관측하여 평균을 내면 통계적 확률로 표현할 수 있는 데 태양빛에서 가장 많이 방사되는 빛의 파장은 노란색파장이고 파장에 따라 다른 강도를 나타냅니다. 이때 파장에 따라 강도를 표현한 것을 태양빛의 스펙트럼이라고 하며 파장을 확률변수로 하는 확률분포라고 할 수 있습니다.
연속형 변수에 적용하는 수체계
범주형 확률변수
범주형 확률변수(nominal random variable)는 확률실험에서 개체가 발생하는 범주에 하나의 확률값(확률질량)을 가집니다. 범주형 확률변수도 고유한 확률분포를 가집니다. 범주형 확률변수값은 기호나 단어입니다. 기호는 크기나 순서의 의미가 없는 숫자일 수도 있습니다. 한편, 기호나 단어가 순서를 나타낼 수 있고 범주를 순서에 따라 정렬할 수 있습니다. 이때 기호나 단어는 순서를 나타내는 기호나 단어를 사용합니다. 그리고 순서를 나타내는 범주를 수준(level)이라고도 합니다. 예를 들면, 과녁, 한우등급 등입니다.
범주형 확률변수의 확률분포 : 확률질량(probability mass)으로 표현
확률질량함수 $f(x)$는 범주형 확률변수 $X$가 $x$를 변수값으로 가질 때의 확률입니다.
$$f(x)=P(X=x)$$
모든 $x$에 대한 $f(x)$의 합은 1입니다.
$$\sum\limits_{{\rm all} \,\, x}f(x)=1$$
확률의 공리에 따라 0에서1까지의 범위를 갖습니다.
$$0 \leq f(x) \leq 1$$
이산형 확률변수
확률변수 $X$의 $R_X$가 유한집합 또는 셀 수 있는 무한집합의 경우, 확률변수, $X$를 이산형 확률변수(discrete random variable)라고 합니다.
이산형 확률변수의 확률분포 : 확률질량함수 (probability mass function)와 누적분포함수(cumulative distribution function)로 표현
확률질량함수 $f(x)$는 확률변수 $X$가 $x$를 변수값으로 가질 때의 확률입니다.
$$f(x)=P(X=x)$$
모든 $x$에 대한 $f(x)$의 합은 1입니다.
$$\sum\limits_{{\rm all} \,\, x}f(x)=1$$
확률의 공리에 따라 0에서1까지의 범위를 갖습니다.
$$0 \leq f(x) \leq 1$$
연속형 확률변수
확률변수 $X$ 의 $R_X$가 셀 수 없는 무한집합의 경우, 확률변수 $X$를 연속형 확률변수(continuous random variable)라고 합니다.
연속형 확률변수의 확률분포 : 확률밀도함수(probability density function)와 누적분포함수(cumulative distribution function)로 표현
확률밀도 함수 $f(x)$는 확률변수 $X$가 변수값 $x$에 대해 밀집된 정도를 나타내는 함수입니다. 확률밀도함수를 수식으로 나타내면 다음과 같으며, 여기서 $X$는 연속형 확률변수이고 $a$와 $b$는 상수입니다.
$$P(a\lt X\lt b)=\int_a^b f(x)dx$$
확률밀도함수는 양의 함수여야 합니다.
$$0 \leq f(x)$$
$-\infty$에서 $+\infty$까지 확률밀도함수를 적분했을 때의 값은 1이 됩니다.
$$\int_{-\infty}^{\infty}f(x)dx=1$$
연속형 확률변수 $X$가 어떤 특정한 값을 가질 확률은 0입니다.
$$𝑃(𝑋=𝑥)=0$$
따라서, 지지집합(support) 원소인 $a$, $b$에서 다음의 4가지 확률이 같습니다. 즉, 연속형 확률변수의 확률값은 확률변수의 구간의 등호에 영향을 받지 않습니다.
$$𝑃(𝑎 \lt 𝑋 \lt 𝑏)=𝑃(𝑎 \leq 𝑋 \lt 𝑏)=𝑃(𝑎 \lt 𝑋 \leq 𝑏)=𝑃(𝑎 \leq 𝑋 \leq 𝑏)$$
범주형 확률변수의 기대비율
확률변수값의 기대비율
범주형 확률변수($X$)의 실현값(realized value, x)을 각 범주명(group name)으로 하면 범주형 확률변수를 다음과 같이 표현할수 있습니다.
$$X=\{g_1, g_2, \cdots, g_n \}$$
여기서, $X$는 범주형 확률변수 또는 표본공간(sample space)
$g_1, g_2, \cdots, g_n$ 은 범주(group)
$n$은 확률변수값의 수
범주형 확률변수값인 각 범주는 대응하는 확률질량을 가지고 있습니다.
$$P(g_i)=p_i$$
여기서, $p(g_i)$는 $g_i$범주의 확률질량
$p_i$는 $i$번째 범주의 확률질량
만일, 한 사건(event)를 $A$라 하고 $A$사건이 안 일어나는 사건을 $A^C$라 하면 사건과 그 사건의 여사건을 확률변수값으로 가지는 범주형 확률변수라고 할 수 있습니다. 이때 두 범주의 기대비율의 합은 1입니다. 연속형 속성의 구간을 나누어 범주를 만든 경우는 기대비율을 범주의 경계점으로 볼 수 있습니다.
$${\rm E}[P(A)]+{\rm E}[P(A^C)]=p+(1-p)=1$$
여기서, ${\rm E}[P(A)]$는 A사건이 일어나는 기대비율의 기대값이고 값은 $p$
이때 두 범주의 비를 odds(오즈)라고 합니다.
$$odds=\dfrac{p}{1-p}$$
2개 범주가 있는 경우 기대비율의 경계의 기대값과 분산
명목이나 순서로 구분되는 범주가 2개 있는 경우, 각 범주는 각 범주에서 발생하는 개체의 발생비율의 비율은 실수로 표현할 수 있습니다. 더 나아가 두 범주의 기대비율의 경계인 $p$ 또는 $1-p$는 0과 1사이 실수의 한 점(point)으로 나타납니다. 이 점은 확률변수로 볼 수 있습니다. 따라서 기대값과 분산을 가집니다.
$p$의 기대값은
$$\rm{E}[P]=p$$
$p$의 분산은
$$\rm{Var}[P]=p(1-p)$$
확률변수 속성, 이산형과 연속형 비교
연속형 변수의 경우 변수값의 실현은 비례척도를 적용한 관측도구에 의해 나타납니다. 따라서 연속형 확률변수은 기대값과 분산은 의미가 있습니다. 하지만 이산형 확률변수의 경우에는 비례척도가 적용된 관측도구로 구한 실현값(realized value)은 기대값과 분산이 의미가 있지만 간격척도가 적용된 관측도구를 사용한 경우에는 위치를 나타내는 기대값은 의미가 있지만 분포의 양을 나타내는 분산을 구할 때는 기준의 위치와 분산은 크기를 반드시 고려해야 합니다.
확률변수값의 평균과 확률변수의 기대값
확률변수는 고유한 확률의 분포를 가지고 있으므로 확률변수를 변수뿐만 아니라 범주로도 볼 수 있습니다. 따라서 범주의 속성을 나타내는 측도(measure)로 확률변수의 확률분포를 설명할 수 있습니다. 확률분포의 중심위치인 평균과 평균으로부터 얼마만큼의 양만큼 흩어져 있는지를 나타내는 분산은 측도(measure)라고 할 수 있습니다. 확률변수의 평균은 확률분포의 중심위치이고 0의 분산을 가지는 범주를 의미하기도 합니다.
확률변수($X$)의 실현값(realized value, x)의 평균(mean)의 표기는 그리스문자 $\mu$입니다.
확률변수($X$)의 기대값(expected value)은 ${\rm 𝐸}[𝑋]$로 표기합니다.
그리고 실현된 확률변수값($x$)의 평균과 그 확률변수($X$)의 기대값($\rm 𝐸[𝑋]$)은 같습니다.
$$\mu_X={\rm E}[X]$$
이산형 확률변수일 때 확률변수의 기대값
$${\rm E}[X]=\sum_{\text{all X}}xf(x)$$
연속형 확률변수일 때 확률변수의 기대값
$${\rm E}[X]=\int_{-\infty}^{\infty}xf(x)dx$$
확률변수값의 평균과 확률변수의 분산
확률변수의 분산은 기준점으로 부터 확률변수값이 흩어진 정도를 나타내는 측도(measure)입니다. 만일, 기준점이 실현된 확률변수값의 평균으로 표현되는 경우는 그리스문자 $\sigma^2$로 표기합니다. 기준점이 기대값으로 표현되는 경우는 분산은 ${\rm Var}[X]$로 표기합니다.
$$\sigma_X^2={\rm Var}[X]={\rm E}[X-\mu]^2={\rm E}[X^2]-\mu_X^2$$
여기서, ${\rm E}[X^2]=\sum\limits_{all \, X}x^2f(x)$
이산형 확률변수의 분산
$${\rm Var}[X]=\sum_{all \, X}(x-\mu)^2f(x)$$
연속형 확률변수의 분산
$${\rm Var}[X]=\int_{-\infty}^{\infty}(x-\mu)^2f(x)dx$$
Terminology
시행
확률이론에서, 실험이나 시행은 무한히 반복되어 행해 질 수 있고 표본공간으로 알려진 가능한 모든 결과의 집합을 얻는 과정을 말합니다. 실험은 하나 이상의 결과가 있을 경우는 “무작위”로, 하나만 있는 경우는 “결정적”으로 표현합니다. 예를 들면, 2 가지(결과는 상호 배타적) 가능한 결과를 갖는 무작위 실험은 베르누이 시험이 있습니다.
실험이 수행 될 때, 시행의 결과는 보통 하나로 나타납니다. 그 결과는 모든 사건에 포함됩니다. 이 모든 사건은 시행에서 발생했다고 말합니다. 같은 실험을 여러 번 수행하고 결과를 모으고 나면 실험자는 실험에서 발생할 수 있는 다양한 결과 및 사건의 경험적 확률을 평가하고 통계분석방법을 적용할 수 있습니다.
출처
확률
확률은 사건이 일어날 가능성을 정량화하는 척도입니다. 확률은 0에서 1 사이의 숫자로 정량화됩니다. 여기서, 0은 불가능함을 나타내며 1은 확실함을 나타냅니다. 시행(event)의 확률이 높을수록 시행이 발생할 가능성이 큽니다. 간단한 예가 동전 던지기입니다. 동전 던지기는 결과가 명확하게 두 가지 결과인 “앞면(Head)”와 “뒷면(Tale)”으로 나타납니다. 그리고 쉽게 앞면과 뒷면의 확률은 동일하다고 동의가 이루어집니다. 다른 결과가 없기 때문에 “앞면”또는 뒷면”의 확률은 1/2 (0.5 또는 50 %)입니다.
이러한 확률개념은 수학, 통계, 금융, 도박, 과학 (특히 물리학), 인공지능, 기계 학습, 컴퓨터 과학, 게임 이론 등과 같은 분야에 공리적 수학적 형식화를 제공합니다. 빈도에 관한 추정을 이끌어내거나 복잡한 시스템의 기본 역학 및 규칙성을 기술하는 데에도 사용됩니다.
출처
확률분포
확률이론 및 통계에서 확률분포는 실험에서 가능하고 서로 다른 모든 결과의 출현 확률을 제공하는 수학적 기능입니다. 보다 기술적인 측면에서, 확률분포는 사건의 확률의 관점에서 임의의 현상에 대한 기술입다. 예를 들어, 확률 변수 $X$가 동전 던지기( “실험”) 결과를 나타내는 데 사용되면 $X$의 확률 분포는 $X$ = 앞면의 경우 0.5, $X$ = 뒷면의 경우 0.5를 취합니다( 동전은 공정). 임의의 현상의 예에는 실험이나 조사의 결과가 포함될 수 있습니다.
확률분포는 관찰되는 임의의 현상의 모든 가능한 결과 집합인 기본 표본공간(sample space)의 관점에서 지정됩니다. 표본공간은 실수 집합 또는 벡터 집합일 수도 있고 비 숫자 값 목록일 수도 있습니다. 예를 들어, 동전 뒤집기의 샘플 공간은 {앞면(Head), 뒷면(Tail)}입니다. 확률 분포는 일반적으로 두 가지로 나뉩니다. 이산 확률분포 (동전 던지기 나 주사위와 같이 가능한 결과 집합이 불연속인 시나리오에 적용 가능)는 확률질량함수라고하는 결과의 확률에 대한 개별 목록으로 표시할 수 있습니다. 반면, 연속확률분포 (주어진 날의 온도와 같이 연속적인 범위 (예 : 실수)의 값을 취할 수 있는 시나리오에 적용 가능)는 일반적으로 확률 밀도함수 (임의의 개별 결과가 실제로는 0인 확률)로 표현할 수 있습니다. 정규 분포는 일반적으로 자주 나타나는 연속확률분포입니다. 지속적인 시간에 정의 된 확률론적 과정과 관련된 복잡한 실험은 더 일반적인 확률측정법의 사용을 요구할 수 있습니다.
표본공간이 1차원인 확률분포 (예 : 실수, 레이블 목록, 정렬된 레이블 또는 이진수)는 단 변수이라고 불리우는 반면 표본공간이 2차원 이상의 벡터 공간 인 분포를 다 변수라고합니다. 단일 변수(변량) 분포는 다양한 대체 값을 취하는 단일 확률변수의 확률을 제공합니다. 다 변수 분포 (합동확률분포)는 다양한 값의 조합을 취하는 임의의 벡터 (두 개 이상의 임의변수를 원소로 가짐)의 확률을 제공합니다. 중요하고 공통적으로 발생하는 단 변량 확률분포에는 이항분포, 초기 하분포 및 정규분포가 포함됩니다. 다 변수 정규 분포는 일반적으로 발생하는 다 변수 분포입니다.
출처
연속, 불연속 변수
수학에서 변수는 연속이거나 이산일 수 있습니다. 두 개의 특정 실제 값 (예 : 임의의 가까운 값) 사이의 모든 실제 값을 취할 수 있는 경우 변수는 해당 간격에서 연속입니다. 변수가 가질 수 있는 값을 포함하지 않는 극한의 간격이 양측에 존재하는 값을 취할 수 있다면, 그 변수값을 중심으로 변수는 분리되고 그 변수는 이산형 변수입니다. 일부 상황에서는 변수가 선상의 일부 범위에서 이산이고 다른 변수에서는 연속일 수 있습니다.
출처
확률변수
확률이론 및 통계에서 임의의 양, 임의의 변수, 즉 확률변수는 비공식적으로 값이 임의의 현상의 결과에 의존하는 변수로 설명됩니다. 확률변수에 대한 공식적인 수학적 설명은 확률이론의 주제입니다. 그 맥락에서, 확률변수는 결과가 일반적으로 실수인 확률공간에서 정의된 측정 가능한 함수로 이해할 수 있습니다.
확률변수의 가능한 값은 아직 수행되지 않은 실험의 가능한 결과 또는 이미 존재하는 값 불확실한 과거 실험의 가능한 결과인 경우를 나타내는 이미 존재하는 값으로 나타낼 수 있습니다 (예 : 부정확한 측정 또는 양자 불확실성으로 인해). 그들은 또한 개념적으로 “객관적”무작위 과정의 결과 또는 양에 대한 불완전한 지식으로 인한 “주관적인”무작위성”을 나타낼 수 있습니다. 확률변수의 잠재 가치에 할당된 확률의 의미는 확률 이론 자체의 일부가 아니며 확률의 해석에 대한 철학적 주장과 관련이 있습니다. 수학은 사용되는 특정 해석과 상관없이 동일하게 작동합니다.
함수로서 확률변수는 측정 가능해야 하며 확률은 잠재가치 집합으로 표현할 수 있습니다. 결과는 예측할 수 없는 몇 가지 물리적 변수에 달려 있을 수 있습니다. 예를 들어, 공정한 동전 던지기의 경우, 앞면 또는 뒷면의 최종 결과는 불확실한 동전의 물리적 조건에 달려 있습니다. 관찰되는 결과는 확실하지 않습니다. 동전의 표면에 균열이 생길 수 있지만 이러한 가능성은 고려 대상에서 제외됩니다.
확률변수의 존재 지역은 표본공간이며 임의의 현상의 가능한 결과의 집합으로 해석됩니다. 예를 들어, 동전 던지기의 경우 두 가지 가능한 결과, 즉 앞면 또는 뒷면이 그러합니다.
확률변수는 확률분포를 가지며, 확률분포는 확률변수의 확률값을 지정합니다. 무작위 변수는 이산형일 수 있습니다. 즉, 임의의 변수의 확률분포의 확률 질량함수 특성이 부여된 유한한 값 또는 계산 가능한 값에서 하나를 취합니다. 또는 임의의 변수의 확률분포의 특징 인 확률밀도함수를 통해 간격 또는 연속된간격에서 임의의 수치 값을 취하는 연속 또는 두 유형의 혼합물 일 수 있습니다.
동일한 확률분포를 갖는 두 개의 확률 변수는 다른 확률 변수와의 관련성 또는 독립성 측면에서 다를 수 있습니다. 무작위 변수의 실현, 즉 변수의 확률분포 함수에 따라 무작위로 값을 선택한 결과를 무작위 변수라고 합니다.
출처
Reference
본인의 Google 계정으로 구글시트를 복사
=BINOM.INV(1,RAND(),0.5) : 50%(0.5) 확률의 사건을 1번 시도해서 나올 수 있는 결과.
=RAND() : 0이상 1미만의 난수를 반환.
=AVERAGE(H3:H102) : 평균. H3에서 H102까지 데이터의 평균. 데이터를 모두 더한 후, 개수로 나눈 산술평균.
=SUM(H3:H102) : 합계. H3에서 H102까지 데이터의 합계.