[QA]
QA > 모델링 > 통계모델
중심극한정리 ?
ARTICLE CONTENTS
Central limit theorem
중심극한정리
확률변수, $X_1, X_2, \cdots, X_n$가 서로 독립하며 평균, $\mu$와 분산, $\sigma^2$을 갖는 동일한 분포를 따른다고 가정합니다. 여기서, 동일한 확률은 임의의 확률분포이며 분포함수가 알려진 확률분포일 필요는 없습니다. 동일한 확률분포를 가지는 $n$개의 확률변수들의 합을 $S_n$이라고 하면 $S_n$도 확률변수입니다.
$$S_n=X_1+X_2+\cdots+X_n$$
여기서, $X_i$는 확률변수 : $i=1, 2, \cdots , n$
$n$이 $\infty$로 커질수록 확률변수, $S_n$은 평균이 $n\mu$이고 분산이 $n\sigma^2$인 정규분포를 나타냅니다.
$$S_n \sim N(n\mu, n\sigma^2)$$
여기서, $\mu$는 확률변수 $X_i$의 동일한 모평균
$\sigma^2$은 확률변수 $X_i$의 동일한 모분산
$n$은 확률변수의 더해지는 수 : $n \rightarrow \infty$
새로운 확률변수인 $S_n$의 확률분포는 합해지는 확률변수의 개수, $n$이 커질수록 확률변수의 분포에 상관없이 정규분포에 수렴합니다. 이를 중심극한정리라고 합니다. 중심극한정리는 정규분포의 중요성을 나타내는 통계학(statistics)의 핵심 정리입니다. 모집단으로 부터의 표본추출과 표본평균 표집의 확률분포 모델링에 사용됩니다.
$$\dfrac{S_n-n\mu}{\sqrt{n\sigma^2}} \xrightarrow{as\ n \to \infty} N(0,1)$$
여기서, $\mu$는 확률변수, $X_i$의 동일 평균
$\sigma^2$은 확률변수, $X_i$의 동일 분산
$n$은 더해지는 동일 확률변수의 수 : $n \rightarrow \infty$
중심극한정리에서는 독립이고 동일한 분포를 가지는 확률변수의 합을 표현하는 새로운 확률변수의 누적분포함수를 표현할 수 있습니다. 확률변수의 개수가 무한대로 갈수록 확률변수의 합을 나타내는 새로운 확률변수는 표준화된 정규분포의 누적분포함수($\Phi(x)$)로 표현할 수 있습니다.
$$\lim_{n\to\infty}P\left(\dfrac{\displaystyle\left(\sum_{i=1}^{n}X_{i}\right)-n\mu}{\dfrac{\sigma}{{\sqrt{n}}}}\leq x\right)= \Phi\left(x\right)$$
$n$이 커지는 과정에서의 표본평균 표집의 확률분포의 변화는 t분포로 표현할 수 있습니다.
표본평균 표집과 중심극한정리
중심극한정리(Central Limit Theorem)는 표본평균을 계산하는 과정에서 극단적인 값들이 서로 상쇄되어 표본평균이 집단의 모평균으로 모이는 경향을 말합니다. 표본크기($n$)가 크면 표본평균의 표집의 분산은 작아집니다. 즉, 표본평균 표집의 확률분포(sampling distribution of sample mean)는 표본의 크기가 커질수록 정규분포의 종모양(bell shape)이 되면서 뽀족해집니다.
평균 $\mu$, 분산 $\sigma^2$인 모집단에서 크기가 $n$인 선택가능한 모든 표본을 뽑으면 모집단의 분포모양과는 상관없이 표본평균들의 확률분포는 표본의 크기($n$)를 증가시킬수록 정규분포에 접근합니다. 즉, 표본평균의 확률분포는 모집단의 평균(모평균)을 중심으로 하는 정규분포를 나타냅니다. 이를 중심극한정리라고 합니다.
모평균과 가능한 모든 표본평균들 사이의 관계는 모집단이 정규분포를 가지지 않아도 정규분포로 관찰됩니다. 만일, 집단이 매우 크면 가능한 모든 표본들을 모두 찾아서 표본평균 표집의 확률분포를 완벽하게 구하는 것은 불가능합니다. 이를 해결하기 위하여 다음과 같은 이론을 정립하였습니다. 이를 중심극한정리(Central Limit Theorem)라고 합니다.
– 모집단이 정규분포 ${\rm N}(\mu,\sigma^2)$라면 표본평균의 표집의 확률분포는 정규분포이고 ${\rm N}\left(\mu,\dfrac{\sigma^2}{n}\right)$로 표현한다.
– 모집단이 모평균이 $\mu$이고 모분산이 $\sigma^2$인 무한히 큰 집단이라면 표본의 크기($n$)가 충분히 클 때 모집단이 어떠한 분포라도 표본평균 표집의 확률밀도함수는 근사적으로 정규분포이고 ${\rm N}\left(\mu,\dfrac{\sigma^2}{n}\right)$로 표현한다.
모집단을 나타내는 확률변수가 평균이 $\mu$이고 분산 $\sigma^2$인 임의의 확률분포를 가질 때 크기가 $n$인 표본을 단순임의복원추출하면 표집(sampling)한 표본평균들의 확률분포(표본평균 표집의 확률분포)는 다음과 같은 특성을 갖습니다.
– 가능한 모든 표본에서 표본평균 표집의 평균(${\mu}_{\bar{x}}$)은 모집단의 평균(모평균)과 같다.
$$\mu_\bar{x}=\mu$$
– 가능한 모든 표본에서 표본평균 표집의 분산($\sigma_{\bar{X}}$)은 모집단의 분산(모분산)을 표본크기($n$)로 나눈 값이다
$$\sigma_{\bar{X}}^2=\dfrac{\sigma^2}{n}$$
– 가능한 모든 표본평균들의 분포는 근사적으로 정규분포이다.
$${\bar X}\sim{\rm N}\left(\mu{,}\dfrac{\sigma^2}{n}\right)$$
표본평균 표집의 정규성
모집단의 확률분포와 표본크기에 따른 표본평균 표집의 확률분포는 달라집니다. 중심극한정리에 의해 표본크기가 30보다 크면 표본평균 표집의 확률분포는 정규분포에 근사한다고 주장할 수 있습니다. 그렇지만 아래 그림과 같이 모집단의 확률분포모양이 쌍봉을 가지면 표본크기를 크게 하여야 표본평균 표집의 확률분포가 정규성을 나타냅니다. 아래그림은 모집단의 확률분포의 모양과 표본크기에 따른 표본평균 표집의 확률분포 모양의 변화를 보여줍니다.
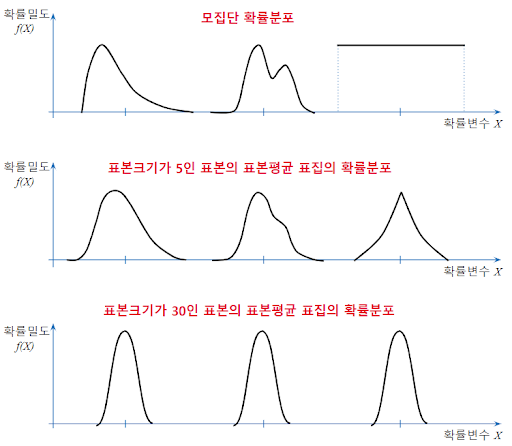
표본평균과 표본분산의 기대값과 표본평균의 표준화(Z변환)
랜덤하게 추출된 표본의 크기가 $n$인 표본은 다음식으로 표현할 수 있습니다.
$$X_1, X_2, \cdots, X_n$$
표본의 평균은 다음식으로 구할 수 있습니다.
$$\bar{X} = \dfrac{1}{n}\sum_{i=1}^{n} X_i$$
모집단의 평균($\mu$)을 안다면, 모집단의 확률분포를 모르더라도 중심극한정리에 의해서 표본평균의 기대값은 모집단의 평균(모평균)이 됩니다.
$${\rm E}[\bar{X}] = \mu$$
집단의 확률분포를 모르더라도 중심극한정리에 의해서 표본분산의 기대값은 집단의 모분산($\sigma^2$)이 됩니다.
$${\rm {Var}}[\bar{X}] = \dfrac{\sigma^2}{n}$$
모집단이 정규분포를 나타내면 표본평균($\bar{X}$)은 확률변수이며 중심극한정리에 의하여 정규분포를 가집니다. 표본평균을 다음과 같이 표준화하여 새로운 확률변수를 생성할 수 있습니다. 이 새로운 확률변수, $Z$는 표준정규분포를 따릅니다.
$$Z=\dfrac{\bar{X} – \mu}{\dfrac{\sigma}{\sqrt{n}}}\sim N\left(0,1\right)$$
정리하면, 모집단이 다음과 같이 정규분포를 가진다면,
$$X \sim N\left(\mu, \sigma^2\right)$$
표본크기가 $n$인 표본평균, $\bar{X}$는 정규분포를 따르며 다음식으로 표현할 수 있습니다.
$$\bar{X} \sim N\left(\mu, \dfrac{\sigma^2}{n}\right)$$
그리고 $\bar{X}$를 표준화하면 즉, Z변환하면 그 표준화식과 표준화한 확률션수 $Z$의 분포를 다음식으로 표현할 수 있습니다. 확률변수 $Z_n$의 아래첨자 $n$은 표본크기를 의미합니다.
$$Z_n = \dfrac{\bar{X} – \mu}{\dfrac{\sigma}{\sqrt{n}}} \sim N \left(0,1\right)$$
Terminology
중심극한정리(central limit theorem)
확률이론에서 중심극한정리(CLT, Central Limit Thorem)는 독립변수가 추가될 때, 어떤 조건에서는 원래 변수가 정규분포가 아니더라도 표준화된 합(예를 들면 표본크기로 표준화된 표본평균)이 정규분포(일명 “종 모양”)에 가까워진다는 것을 말합니다. 이 이론은 정규분포에 적용되는 확률 및 통계 방법이 다른 형식의 분포를 가지는 많은 경우에도 사용될 수 있음을 나타내기 때문에 확률에서 매우 중요합니다.
예를 들어, 다수의 측정값으로 구성된 표본이 있고, 각 측정값은 다른 측정값과 관계없이 무작위로 생성되고 그 값들의 산술평균을 계산한다고 가정해 봅니다. 이 과정이 여러 번 이루어진다면, 중심극한정리에 따라 이 평균의 분포는 정규분포에 근사합니다. 간단한 예로 동전을 여러 번 던질 경우 앞면이 몇 번 나올지에 대한 확률분포는 던진 횟수의 절반이 평균이 되는 정규분포에 가까워집니다(무한대로 던지게 되면 정규 분포와 같게 됩니다).
중심극한정리는 여러가지의 변형된 정리가 있습니다. 일반적인 형태에서는 확률변수가 동일하게 존재하여야 합니다. 하지만 변형된 정리에서는, 평균의 확률분포의 정규분포로에 대한 근사는 조건만 만족한다면 동일하지 않은 분포나 독립적이지 않은 측정에서도 일어납니다. 이 정리의 처음 형태(정규분포를 이항분포에 대한 근사로 사용할 수 있다)는 현재 드므와르 라플라스 정리로 알려져 있습니다.
Reference
Central limit theorem – Wikipedia
모집단(population)
통계에서 모집단은 질문이나 실험(experiment)의 대상이 되는 유사성을 가지는 분류 또는 사건의 집합입니다. 통계적 모집단은 실재하는 물건(예를 틀어 우주에 있는 모든 항성의 집합)일 수도 있고 경험을 통해 일반화된 잠재적으로 무한한 집단(포커에서 가능한 모든 패의 집단)일 수 있습니다. 통계분석의 공통적인 목표는 선택된 모집단에 대한 정보를 산출하는 것입니다.
통계적 추론(statistical inference)에서 모집단의 부분집합인 표본은 통계적 분석으로 모집단을 나타내기 위해 선택됩니다. 이 표본의 크기와 모집단의 크기의 비율을 표본분수(sampling fraction)라고 합니다. 적절한 표본에 대해 통계를 사용해 모집단 매개변수를 추정할 수 있습니다.
Reference
표본(sample)
통계와 양적 연구방법론에서 표본은 수집된 데이터집합이며 정해진 절차에 따라서 통계적 모집단에서 선택된 또 다른 집단입니다. 표본의 요소(elements)는 표본점(sample points), 표본추출 단위(sampling units) 또는 관측대상(observations)이 있습니다.
일반적으로 인구는 매우 큰 집단이므로 전체 인구조사와 인구집단에 대한 완전한 서술은 불가능하고 효용이 없습니다. 표본은 일반적으로 관리가 가능할 정도의 크기의 모집단의 하위 집합을 나타냅니다. 표본을 수집하고 표본에서통계량을 계산하면 표본을 통해 모집단을 추론할 수 있게 됩니다. 추론(inference)에는 대표적으로 추정(estimation)과 가설검정(hyperthesis test)이 있습니다. 그리곡 추정에는 점추정과 구간추정이 있습니다. 이 모든 것이 표본을 통해 모집단의 정보를 알아 내는 것입니다.
표본은 비복원(같은 표본이 여러번 선택되는 경우가 없는 경우)으로 추출될 수 있고, 이 경우에는 표본은 모집단의 부분집합이 됩니다. 복원추출을 한 경우는 다중부분집합이 됩니다.
Reference
표집분포(표본분포, sampling distribution or finite-sample distribution)
통계에서 표본분포는 표집분포(sampling distribution) 또는 유한표본분포( finite-sample distribution)라 불리우기도 합니다. 표본분포는 정해진 무작위 표본추출을 기반으로 한 확률분포입니다. 여러가지의 관측(observations)결과가 있는 매우 많은 표본의 통계량(예를 들어 표본평균 또는 표본분산)을 계산한다면, 표본분포는 그 표본이 가지는 확률변수의 확률분포라고도 할 수 있습니다. 따라서 많은 경우, 하나의 표본을 관찰하고 표본분포는 이론적으로 구합니다.
표본분포는 통계적 추론(statistical inference)을 위한 핵심 단순화과정이기 때문에 통계에서 매우 중요합니다. 보다 구체적으로, 표본분포의 분석시 고려사항은 표본통계량의 공동확률분포(joint probability distribution)보다는 모집단(통계집단) 확률분포의 조사 기반으로의 사용입니다.