[DATA SCIENCE]
데이터사이언스 > 데이터 > 데이터시각화 > 개체의 시각화
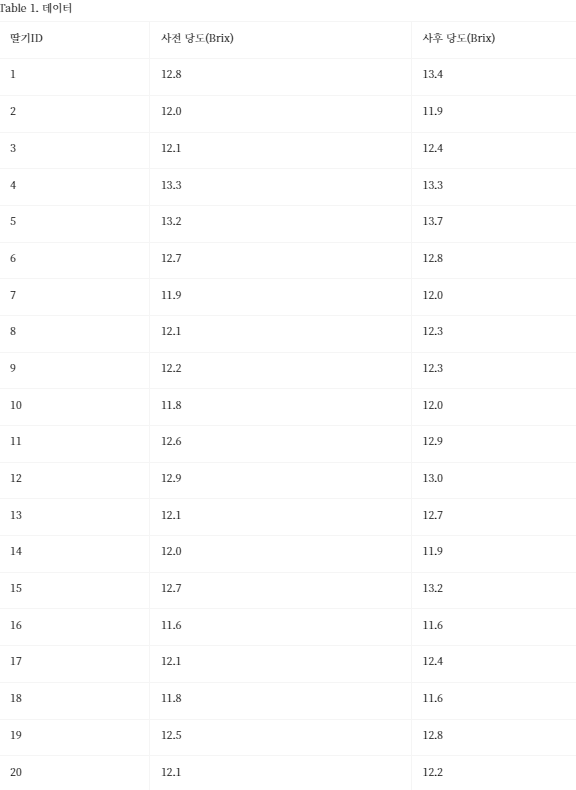
한 범주형변수로 구분된 여러 집단 모평균 비교: 일원분산분석 F검정
[Q&A]
집단이 2개 일 때 일원분산분석 F검정과 t검정의 결과가 같은 이유
ARTICLE CONTENTS
Comparison of population means among multiple groups divided by a categorical variable: One-way ANOVA F-test
DataLink Research Group
Author
DataLink Research Group
Citation
DataLink Research Group. 2023. Comparison of population means among multiple groups divided by a categorical variable: One-way ANOVA F-test, DataLink, s24-2-1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
일원분산분석은 범주형 독립변수와 연속형 종속변수 간의 관계를 분석하는 통계적 방법입니다. 예를 들어, 품종에 따른 딸기의 당도 차이, 흡연여부에 따른 사람의 생애진료비 차이 등은 연구주제가 될 수 있습니다. 이 분석에서 범주형 독립변수의 범주로 인한 종속변수의 평균차이가 통계적으로 유의미한 지를 검정하는 F검정을 수행합니다. F 검정은 2개 이상의 집단 간 비교에 사용되며, 집단이 2개일 때는 t검정의 결과와 같습니다. 일원분산분석은 정규성, 등분산성, 그리고 독립성의 가정을 기반으로 합니다. 가설검정은 총변동을 집단내변동과 집단간변동으로 분할하여 집단 간 평균차이의 유의성을 F값을 통해 평가합니다. 분석 결과가 유의미할 경우, 사후 분석을 통해 어느 집단 간에 차이가 있는지 구체적으로 파악합니다. 일원분산분석은 실험 디자인, 사회과학, 의료 연구 등 다양한 분야에서 폭넓게 활용됩니다.
Key Word
범주형, 연속형, 총변동, 집단, 모평균, 일원분산분석, F검정
개체와 집단
집단(group)은 개체(individual)의 범주형 속성이 같은 개체가 모여 형성됩니다. 범주(categoyr)는 개체(individual)를 구분합니다. 그리고 집단은 범주로 구분된 개체의 집합입니다.
집단의 이름은 범주형 변수의 변수값입니다. 개체의 속성이 집단의 이름으로 설명된다면 집단의 이름과 개체의 속성간에는 함수관계로 설명할 수 있습니다. 개체의 속성을 종속변수로, 집단의 이름을 원인변수라고 봅니다. 이 함수는 집단에 따른 개체의 속성의 다름을 설명합니다.
범주형 변수가 독립변수가 되고 연속형 확률변수가 결과(원인에 따른 반응)변수가 되는 연구주제를 살펴봅니다.
개체의 속성을 확률변수로 모델링할 수 있다면 표본을 추출하여 표본의 분포를 관측하여 개체의 추론할 수 있습니다. 예를 들어, 표본평균으로 모평균을 점추정할 수 있습니다.
집단(그룹)에 따라 달라지는 개체의 속성을 비교하는 연구주제의 예는 다음과 같습니다.
• ‘설향’, ‘아키히메’, ‘장희’의 ‘품종’에 따라 ‘딸기’의 ‘당도’는 다른가?
• ‘흡연’과 ‘비흡연’의 ‘흡연유무’에 따라 ‘사람’의 ‘생애진료비’는 다른가?
‘딸기’와 ‘사람’은 개체(객체, indivisual, object)의 이름입니다. ‘품종’과 ‘흡연유무’는 원인변수(독립변수, 설명변수, 요인, 인자, factor,, 수준, level, 카테고리, category)의 이름입니다. ”설향’, ‘아키히메’, ‘장희’는 ‘품종’이라는 범주형 확률변수의 확률변수값입니다. ‘흡연’, ‘비흡연’은 ‘흡연여부’라는 범주형 확률변수의 확률변수값입니다. 특별히, 범주형 확률변수가 확률변수값이 2개이고 서로 배타적인 경우, 그 범주형 확률변수를 이분형 확률변수라고 부릅니다. 여기서 당도’와 ‘생애진료비’는 범주형 원인변수에 따라 달라지는 결과변수(종속변수, 반응변수)의 이름입니다. 분석의 대상인 ‘딸기’와 ‘사람’의 ‘당도’와 ‘생애진료비’를 연속형 확률변수로 하여 분석을 행합니다.
정리하면, 다음과 같습니다.
첫번째 예에서 원인변수는 변수명이 ‘품종’이고 변수값은 ‘설향’, ‘장희’, ‘아키히메’ 등 3개가 있습니다. 이 원인변수값은 개체가 속하는 범주의 이름을 나타내는 범주형데이터입니다. 그리고 결과변수의 이름은 ‘당도’이고 실수(real number)의 수체계를 가지는 확률변수로 모델링합니다. 이 결과변수값은 연속형데이터입니다.
두번째 예에서 원인변수는 변수명이 ‘흡연유무’이고 변수값은 ‘흡연’과 ‘비흡연’인 2개가 있습니다. 이 원인변수값은 개체가 속하는 범주의 이름을 나타내는 범주형데이터입니다. 특별히 ‘흡연유무’는 ‘흡연’과 ‘비흡연’이라는 변수값만 존재하는 2분형데이터입니다. 즉, ‘사람’이라는 개체는 ‘흡연’과 ‘비흡연’이라는 2개의 범주 중에 한 범주에는 반드시 속합니다. 그리고 결과변수는 ‘생애진료비’이고 실수(real number)의 수체계를 가지는 확률변수로 모델링합니다. 이 결과변수값은 연속형데이터입니다.
분산분석
분산분석(ANOVA, analysis of variance)이 사용되는 경우는 전체집단을 이루는 집단(group, 수준, level, 카테고리, category)이 3개 이상일 때, 각 잡단에서 추출한 표본통계량의 통계적 유의성을 확인할 때 입니다. 집단이 2개인 경우에도 사용할 수 있지만 집단이 2개인 경우는 주로 t검정을 사용하며 결과는 같습니다.
분산분석에 적용되는 변수의 척도를 살펴보면 다음과 같습니다.
결과변수(종속변수): 비율척도(키, 나이, 길이 부피, 시간) 또는 간격척도(온도, 시각, 만족도)
원인변수(독립변수): 명목척도 (성별, 학년, 연령, 번호)
분산분석은 원인이 되는 독립변수의 개수에 따라 일원(One-way), 이원(two-way), 다원(multi-way)으로 구분되고 결과가 되는 종속변수의 개수에 따라 한 개면 단일변량 분산분석, 두 개 이상이면 다변량 분산분석(MANOVA)로 구분합니다.
반면, t검정(t-test)은 모집단에서 추출한 표본이 1개 또는 2개인 경우에 행합니다. 모집단내 3개이상의 집단의 비교를 위해 각 집단에서 추출한 표본을 t검정에 사용하면, 다중검정문제 발생으로 1종 오류가 증가할 수 있기 때문입니다.
분산분석 방법
1) 원인(요인, 중재, 범주형 독립변수, factor, intervention)에 따라 집단(수준, 카테고리, level, category)을 구분하고 원인에 따라 구분된 각 집단의 모평균이 동일한 지를 표본평균을 이용하여 검정합니다. 각 집단의 모평균은 상수로 표본평균은 확률변수로 모델링합니다.
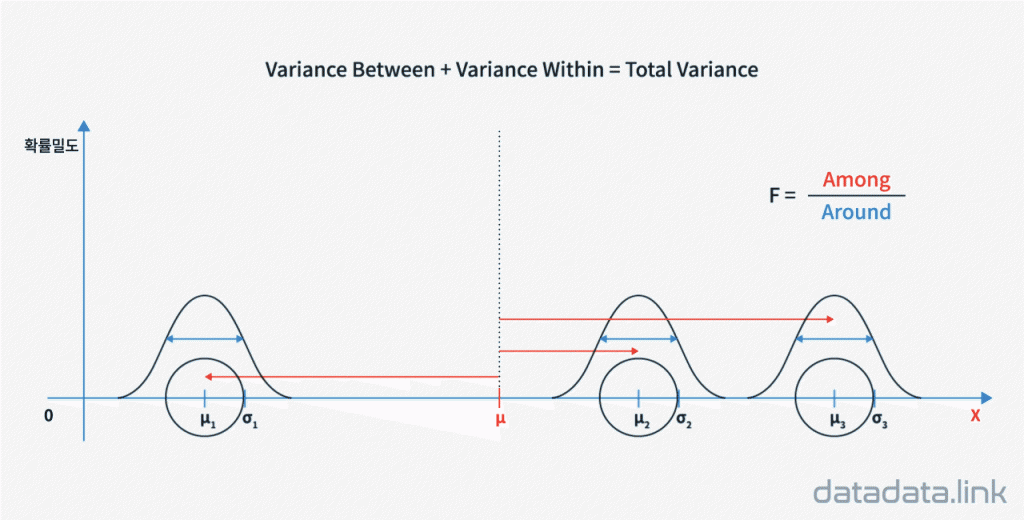
2) 가설을 검정하기 위해 총변동을 원인(factor)에 의해 기인한 부분과 결과를 확률변수로 모델링하여 나타난 부분으로 분할합니다. 원인에 의해 기인한 부분은 집단(범주)의 변동을 의미하고 결과를 확률변수로 모델링하여 나타난 부분은 개체의 변동을 의미합니다. 원인변수에 의한 변동은 ‘집단간분산’으로 표현하며 확률변수로서의 결과변수의 변동은 ‘집단내분산’으로 표현합니다. ‘집단간분산’이 ‘집단내분산’보다 충분히 클 때 원인에 의해 집단의 모평균의 차이가 발생한다고 판단합니다. 신호(signal)가 되는 ‘집단간분산’과 잡음(오차, noise, error)가 되는 ‘집단내분산’의 비로 잡음에 대한 신호의 비로 새로운 확률변수가 만들어지며 표준화된 이 새로운 확률변수를 ‘$F$’로 표기합니다. 새로운 확률변수인 ‘$F$’의 확률분포를 사용하여 검정하는 F검정에서 0점은 ‘집단들의 모평균이 같다’는 귀무가설로 만들어 집니다.
3) 분산분석은 ‘집단의 모평균을 같다(집단의 모평균의 차이가 0이다)’라는 귀무가설을 세우고 확률변수인 ‘집단간분산’과 확률변수인 ‘집단내분산’의 비를 ‘새로운 확률변수’로 하여 가설을 검정하는 방법입니다. 집단의 분산은 그 집단의 표본으로 추정합니다. 이때 ‘집단들의 집단’을 ‘모집단’으로 모델링하여 ‘모든 집단의 모분산이 같다’라는 ‘등분산 가정’을 합니다.
분산분석을 위한 가정
- 정규성 가정 : 모든 집단은 정규분포를 나타낸다.
- 등분산 가정 : 모든 집단의 모분산은 같다.
- 독립성 가정 : 표본내 각 집단은 서로 독립이다.
일원, 이원, 다원 분산분석
전체집단을 이루는 집단들의 모평균을 비교하기 위하여 전체집단과 각 집단의 분산을 분석하는 것을 분산분석(ANOVA, analysis of variance)이라고 합니다.
분산분석중에서 전체집단을 이루는 집단이 한 개의 원인(요인, 인자, factor,, 수준, level, 카테고리, category)변수의 값으로 구분되는 경우, 일원분산분석(one-way ANOVA)이라고 합니다. 두 개의 원인변수의 값의 쌍으로 구분되는 경우를 이원분산분석(two-way ANOVA)라고 합니다. 3개 이상의 원인변수의 조합으로 구분되는 경우는 다원분산분석(Multi-way ANOVA)라고 합니다.
분산분석 구분
| 구분 | 상세구분 | 원인변수의 수 | 결과변수의 수 |
| 단일변량 분산분석 ANOVA | 일원분산분석 (One-way ANOVA) | 1개 (일원) | 1개 |
| 이원분산분석 (Two-way ANOVA) | 2개 (이원) | ||
| 다원분산분석 (Multi-way ANOVA) | 3개 이상 (다원) | ||
| 반복측정 분산분석 (Repeated measures ANOVA) | 1개 (일원) 2개 (이원) | 1개 (대응표본수에 따른 종속변수값의 수는 2개 이상) | |
| 다변량 분산분석 MANOVA | MANOVA | 1개 | 2개 이상 |
사후분석
분산분석은 보통 집단이 3개 이상인 경우에 실시합니다. 집단이 2개 일 때도 사용할 수 있지만 집단이 2개일 때는 주로 t검정을 사용합니다. 분산분석은 표본을 이용하여 집단간의 차이의 여부는 확인 가능하나 차이의 양은 확인이 불가능합니다. 따라서 사후분석을 통해 집단간의 유의성 여부를 확인합니다.
사후분석 방법
| 사후분석 방법 | 설명 |
| Tukey |
|
| Scheffe |
|
| Duncan |
|
| Bonferroni |
|
일원분산분석
일원분산분석(one-way ANOVA, one-way analysis of variance)은 3개 이상의 집단에 대해 독립변수가 1개인 경우 집단 간 종속변수의 대표값 차이를 비교할때 사용합니다.
일원분산분석을 위한 조건은 다음과 같습니다.
- 종속변수는 양적 확률변수이고 간격 혹은 비례척도로 관측한다.
- 확률변수인 종속변수의 모분산을 알지 못할 때 사용한다
- 확률변수인 종속변수의 확률분포가 정규분포이어야 한다
- 정규분포라는 가정이 충족되지 않으면 비모수 통계(non-parametric statistics)를 사용하여야 한다.
분산분석은 표본이 3개 이상인 경우 Z검정이나 t검정을 실시할 수 없을 때 주로 사용합니다. 분산분석은 표본들 간의 차이 여부는 확인가능하나 표본들 간의 양적인 차이는 알 수 없습니다.
분산의 양적인 차이를 분석하기 위하여 사후분석을 실시합니다. 사후분석을 통해 집단간의 유의성 여부도 확인합니다.
실제로 관측되는 결과변수(종속변수, 분석변수, 반응변수, response variable)의 값을 ‘변량’이라고 합니다. 결과변수는 대부분 양적 확률변수이고 이산형 보다는 연속형 확률변수입니다. 따라서 대부분 결과변수의 값은 연속형 데이터입니다. 그리고 원인변수(독립변수, 요인, 설명, 인자, factor)는 전체집단을 이루는 집단을 구분하며 대부분 범주형 변수입니다. 범주형 원인변수는 범주(카테고리, catetory)이며 범주형 원인변수의 값은 범주명이 됩니다. 원인변수의 값이 순서의 정보를 포함하면 그 원인변수를 수준(level)이라고 부르기도 합니다. 수준의 변수값의 개수를 ‘수준 수(number of level)’이라고 합니다. 범주나 수준의 이름의 개수는 관측대상인 집단에 속한 집단의 개수나 관측대상인 개체가 속하는 집단의 개수와 같습니다.
분산분석에서 결과변수(종속변수)가 ‘반응(response)’, 원인변수(독립변수)가 ‘요인(인자, factor)’으로 불라는 이유는 분산분석이 공학, 농학, 의학, 약학 등에서 실험에서 얻은 데이터를 분석하는 데 많이 이용되기 때문입니다. 분산분석 중에서 하나의 요인이 반응변수에 미치는 영향을 조사하는 경우를 일원분산분석(one-way ANOVA)이라고 합니다.
모집단에서 표본을 임의(random)로 추출한 표본에는 모집단에 있는 집단이 나타납니다. 여기서, 집단을 그룹(group)이라고 표현하여 카테고리(category)의 의미를 강조하기도 합니다. 표본은 모집단의 그룹(카테고리)의 정보가 포함됩니다. 모집단에서 그룹(집단)의 개수는 표본에서의 그룹(집단)의 개수와 같다고 가정합니다.
일원분산분석에서 모집단 내 집단의 개수가 $k$ 개이고 각 집단에서의 관측값의 개수가 각각 $n_{1},n_{2},\cdots{,}n_{k}$개인 경우의 표본 데이터(관측값)는 다음 표와 같이 표현할 수 있습니다.
일원분산분석 데이터(One-way ANOVA data)
범주형 원인변수로 구분 | 모평균 | 모분산 | 표본크기 | 표본 데이터(관측값) | 표본평균 | 표본분산 |
| 집단 1 | $\mu_{Y_1}$ | $\sigma_{Y_1}^2$ | $n_1$ | $\begin{array}{cccc}{{y}_{11}}&{{y}_{12}}&{\cdots}&{{y}_{1{n}_{1}}}\end{array}$ | ${\bar{Y}}_{1}$ | $S_{Y_1}^2$ |
| 집단 2 | $\mu_{Y_2}$ | $\sigma_{Y_2}^2$ | $n_2$ | $\begin{array}{cccc}{{y}_{21}}&{{y}_{22}}&{\cdots}&{{y}_{2{n}_{2}}}\end{array}$ | ${\bar{Y}}_{2}$ | $S_{Y_2}^2$ |
| . . . | . . . | . . . | . . . | . . . | . . . | . . . |
| 집단 $k$ | $\mu_{Y_k}$ | $\sigma_{Y_k}^2$ | $n_k$ | $\begin{array}{cccc}{{y}_{k1}}&{{y}_{k2}}&{\cdots}&{{y}_{k{n}_{k}}}\end{array}$ | ${\bar{Y}}_{k}$ | $S_{Y_k}^2$ |
일원분산분석 모델
일원분산분석은 범주형 변수로 구분되는 집단의 분산을 변동과 자유도로 나누어 모델을 만듭니다. 그리고 일원분산분석은 원인변수가 하나인 분산분석입니다. 우선 일원분산분석을 위한 전체집단의 모집단 모델과 전체집단의 표본모델은 다음과 같습니다.
모집단 모델
$$Y_{ij}=\mu_{Y} + \epsilon_{ij} = \mu_{Y}+(\mu_{Y_i}-\mu_{Y})+(Y_{ij}-\mu_{Y_i})=\mu_{Y}+\alpha_{i}+{\varepsilon}_{ij}$$
여기서, $Y_{ij}$는 $i$번째 집단의 $j$번째 값
$\mu_Y$는 모집단의 모평균
$\epsilon_{ij}$는 $i$번째 집단의 $j$번째 값($Y_{ij}$)과 전체집단의 모평균($\mu_Y$)과의 편차: 오차
$\mu_{Y_i}$는 $i$번째 집단의 모평균
$\alpha_i$는 $i$번째 집단의 모평균($\mu_{Y_i}$)과 모집단의 모평균($\mu_Y$)과의 편차
$\varepsilon_{ij}$는 $i$번째 집단의 $j$번째 값($Y_{ij}$)과 $i$번째 집단의 모평균($\mu_{Y_i}$)과의 편차: 오차
오차항 $\epsilon_{ij}$은 서로 독립이며, 평균이 0 이고 분산이 ${\sigma^{2}}$인 정규분포를 따른다고 가정합니다. 오차항 $\epsilon_{ij}$는 집단간의 차이가 아닌 다른 요인에 반응하는 종속변수(반응변수)의 변동을 나타내는 확률변수입니다.
모집단 모델에서 $i$번째 집단에서의 $Y$의 평균($\mu_{Y_{i}}$)을 ($\mu_Y{+}\alpha_{i}$)로 나타내었는데 여기에서 $\mu_Y$는 확률변수 $Y$의 모집단의 평균을 나타내며, $\alpha_{i}$는 $(\mu_{Y_{i}}-\mu_Y)$로 이를 종속변수(반응변수)에 대한 $i$번째 집단의 효과(effect)라고 합니다.
모집단크기 등식
$$N=\sum_{i=1}^{k}N_i$$
여기서, $N$은 모집단의 크기
$k$는 집단의 수
$N_i$는 $i$번째 집단의 크기
표본 모델
$$Y_{ij} = {\bar Y}+(\overline {Y_i}-\bar Y) + (Y_{ij}-{\overline {Y_i}})$$
여기서, $Y_{ij}$는 $i$번째 집단의 $j$번째 관측값
$\bar Y$는 표본평균
$\overline {Y_i}$는 표본내 $i$번째 집단의 평균
$(\overline {Y_i}-\bar Y)$는 표본내 $i$번째 집단의 평균($\overline {Y_i}$)과 표본평균($\bar Y$)과의 편차
$ (Y_{ij}-{\overline {Y_i}})$는 $i$번째 집단의 $j$번째 관측값($Y_{ij}$)과 표본내 $i$번째 집단의 평균$\overline {Y_i}$과의 편차 : 잔차($X_{residual}$, $X_r$)
$k$는 집단의 개수라면, ${i}{=}{1}{,}{2}{,}\cdots{,}{k}$
$n_i$가 표본내 $i$번째 집단의 크기라면, $j=1, 2, \cdots , {n_i}$
표본크기 등식
$$n=\sum\limits_{i=1}\limits^{k}n_{i}$$
여기서, $n$은 표본크기
$n_i$는 표본내 i번째 집단의 개체의 수
변동과 자유도
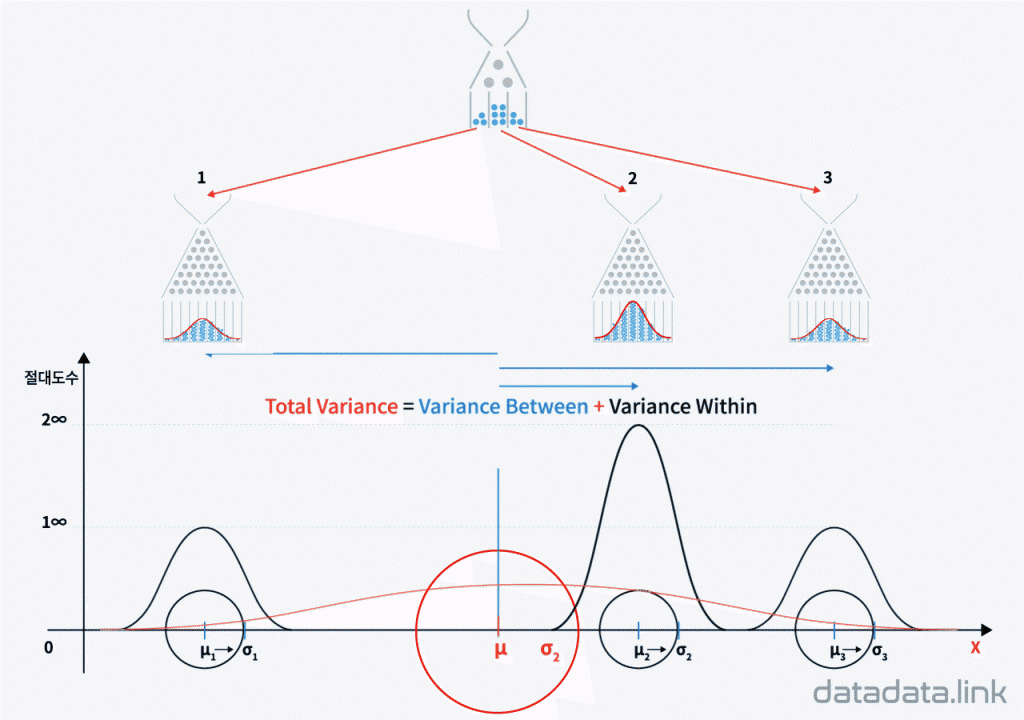
집단의 속성을 나타내는 측도(mearsure)로는 변동(variation)과 자유도(degree of freedom)가 있습니다. 분산분석을 위해 전체집단을 이루는 각 집단의 변동과 자유도를 구합니다. 집단의 변동은 집단의 평균에서의 편차제곱합입니다. 전체집단의 표본은 전체집단을 이루는 각 집단의 표본의 합집합이라고 볼 수 있습니다.
$$Y_{ij} – {\bar Y} = (\overline {Y_i}-\bar Y) + (Y_{ij}-{\overline {Y_i}})$$
윗 식에서 왼쪽 식과 오른쪽 식을 각각 제곱하여 전체표본크기만큼 합하면 다음식과 같습니다.
$$\sum\limits_{i=1}^{k}\sum\limits_{j=1}^{n_i}(Y_{ij}-\bar Y)^2 = \sum\limits_{i=1}^{k}\sum\limits_{j=1}^{n_i}(\overline {Y_i}-\bar Y)^2 + \sum\limits_{i=1}^{k}\sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i})^2$$
결과변수(반응변수, 종속변수)인 $Y$의 관측값들과 총평균 사이의 거리 제곱합으로 이를 총변동(total variation) 또는 총제곱합(total sum of squares, $SS_T$)이라 하고 다음과 같습니다.
$$SS_T=\mathop{\sum}\limits_{i=1}\limits^{k}\mathop{\sum}\limits_{j=1}\limits^{n_i}(Y_{ij}-\overline{Y_{\cdot\cdot}})^2$$
$Y$의 $i$번째 집단(그룹, 수준, 카테고리)에서의 관측값들의 평균 $\overline{Y_i}$은 전체집단의 모평균을 기준으로 $i$번째 집단의 변동을 나타낸 것입니다. 그러므로, 개개의 관측값 대신에 집단의 표본평균을 사용하여 총변동을 구하면(즉, 총제곱합을 구하는 공식에서 $Y_{ij}$ 대신에 $\overline{Y_{i\cdot}}$를 대입하면), 이는 집단의 변동을 나타냅니다. 이와 같은 변동을 집단간 변동(Between variation)이라 하며 이 변동을 나타내는 제곱합을 $SS_{B}$로 표기합니다. 각 집단 간에 발생하는 변동은 다음식으로 표현합니다.
$$SS_{B}=\mathop{\sum}\limits_{i=1}\limits^{k}\mathop{\sum}\limits_{j=1}\limits^{n_i}(\overline{Y_{i\cdot}}-\overline {Y_{\cdot\cdot}})^2=\mathop{\sum}\limits_{i=1}\limits^{k}{n_i}(\overline{Y_{i\cdot}}-\overline{Y_{\cdot\cdot}})^2$$
각 집단내에서 발생하는 변동의 합은 다음과 같습니다.
$$SS_W=\mathop{\sum}\limits_{i=1}\limits^{k}\mathop{\sum}\limits_{j=1}\limits^{n_i}(Y_{ij}-\overline{Y_{i\cdot}})^2$$
각 집단내의 변동을 집단내변동(Within variation)이라 하며, 이 집단내변동을 $SS_W$로 표기합니다.
각 변동이 가지는 자유도는 다음과 같은 논리에 의해 구해집니다. $SS_T$를 계산하기 위해서는 $n$개의 $Y_{ij}$ 값이 있지만, 먼저 전체평균의 추정량인 ${\bar{Y}}$을 구해야 하므로 $SS_T$는 자유도 $(n-1)$을 가집니다. 집단내변동($SS_W$)을 구하기 위해서는 $k$개의 각 집단의 표본평균인 $\overline{Y_{1}},\cdots,\overline{Y_{k}}$를 먼저 구하므로 $SS_W$는 $(n-k)$의 자유도를 가집니다. 집단간변동($SS_{B}$)은 $SS_T$의 자유도에서 $SS_W$의 자유도를 뺀 나머지 $(k-1)$의 자유도를 가집니다.
그리고 다음과 같이 변동의 등식으로 표현할 수 있습니다.
$$SS_T=SS_{B} + SS_W$$
여기서, $SS_{T}$는 총변동
$SS_{B}$는 집단간변동
$SS_{W}$는 집단내변동
집단의 자유도를 분석하기 위하여 전체집단의 자유도와 각 집단의 자유도를 구합니다. 총변동($SS_T$)의 데이터 포인터수는 $n$개이고, 데이터 포인터 중 전체집단의 평균을 구하기 위하여 자유도 1개를 사용하므로 총자유도는 $(n – 1)$입니다. 집단간변동($SS_{B}$)은 $k$개의 집단의 편차제곱합이고, 각 집단의 모평균의 평균인 전체평균 1개를 기준으로 사용하므로 집단간변동의 자유도는 $(k-1)$입니다. 집단내변동($SS_W$)의 자유도는 편차제곱을 구할 때, 각 집단의 평균이 기준이 되므로 전체개수($n$)에서 각 집단의 평균의 개수, 즉 각 집단의 개수 $k$를 뺸 $(n-k)$가 집단내변동($SS_E$)의 자유도입니다, 따라서 다음의 자유도의 관계식이 성립합니다.
$$(n-1)=(k-1) + (n-k)$$
여기서, $n$은 표본의 크기
$k$는 집단의 수
위 자유도 등식은 다음과 같이 표현할 수도 있습니다.
$$df(SS_T) = df(SS_{B}) + df(SS_E)$$
여기서, $df(SS_T)$는 총변동($SS_T$)의 자유도
$df(SS_{B})$는 집단간변동($SS_{B}$)의 자유도
$df(SS_{W})$는 집단내변동($SS_{W}$)의 자유도
총변동의 분할 등식
$$\eqalign {\sum\limits_{i=1}^{k}\sum\limits_{j=1}^{n_i}(Y_{ij}-\bar Y)^2&=\sum\limits_{i=1}^{k}\sum\limits_{j=1}^{n_i}\left[(\overline {Y_i}-\bar Y) + (Y_{ij}-\overline {Y_i})\right]^2\cr &=\sum\limits_{i=1}^{k}\sum\limits_{k=1}^{n_i}\left[(\overline {Y_i}-\bar Y) ^2 + 2(\overline {Y_i}-\bar Y)(Y_{ij}-\overline {Y_i}) + (Y_{ij}-\overline {Y_i})^2\right]^2\cr &=\sum\limits_{i=1}^{k}\left[{n_i}(\overline {Y_i}-\bar Y) ^2 + 2(\overline {Y_i}-\bar Y)\sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i}) + \sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i})^2\right]\cr &=\sum\limits_{i=1}^{k}\left[{n_i}(\overline {Y_i}-\bar Y) ^2 + 2(\overline {Y_i}-\bar Y)\sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i}) + \sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i})^2\right]\cr &=\sum\limits_{i=1}^{k}\left[{n_i}(\overline {Y_i}-\bar Y) ^2 + \sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i})^2\right]}$$
윗식을 전개하는 과정에서 각 집단의 잔차의 합은 $0$이기 때문에 다음식이 사용됩니다.
$$\sum\limits_{j=1}^{n_i}(Y_{ij}-\overline {Y_i})=\sum\limits_{j=1}^{n_i}Y_{ij}-{n_i}\overline {Y_i}=0$$
따라서, 총제곱합은 다음과 같이 표현할 수 있습니다.
$$\sum\limits_{i=1}^{k}\sum\limits_{k=1}^{n_i}(Y_{ij}-\bar Y)^2 = \sum\limits_{i=1}^{k}\sum\limits_{k=1}^{n_i}(\overline {Y_i}-\bar Y)^2 + \sum\limits_{i=1}^{k}\sum\limits_{k=1}^{n_i}(Y_{ij}-\overline {Y_i})^2$$
일원분산분석표
일원분산분석을 위해 일원분산분석표((One-way ANOVA table))를 사용합니다.
일원분산분석표(One-way ANOVA table)
| 변동 (variation) | 변동 표기 (squared sum) | 자유도 (degrees of freedom) | 분산 (variance) | 분산 표기 (mean squared) | $F$검정통계량 (F statistic) |
| 집단간변동 (Between variation) | $SS_B$ | ${k}-{1}$ | 집단내분산 (Between variance) | ${MS_B}=\dfrac{SS_B}{k-1}$ | $F_{0}=\dfrac{MS_B}{MS_W}$ |
| 집단내변동 (Within variation) | $SS_W$ | ${n-k}$ | 집단내분산 (Within variance) | ${MS_W}=\dfrac{SS_W}{n-k}$ | |
| 총 (Total variation) | $SS_T$ 여기서, $SS_T=SS_B+SS_W$ | ${n-1}$ 여기서, $(n-1)=(k-1)+(n-k)$ | 표본분산 (Sample variance) | ${MS_T}=\dfrac{SS_T}{n-1}$ |
검정통계량
분산분석을 하기 위해서 집단간변동($SS_B$)과 집단내변동($SS_W$)을 각각의 자유도로 나누어 집단간분산과 집단내분산을 구합니다.
만일, 집단의 수는 적고 각 집단내 개체의 수가 매우 많으면 집단내변동은 집단간변동에 비해 매우 커질 것입니다. 물론, 그 반대의 경우도 마찬가지 입니다. 이런 경우, 자유도로 나누어 개체의 순서로 표준화한 분산으로 비교하게 됩니다.
집단간분산
$$MS_B=\dfrac{SS_B}{k-1}$$
집단내분산
$$MS_W=\dfrac{SS_W}{n-k}$$
여기서, $MS_B$은 집단간분산
$MS_W$는 집단내분산
F검정의 검정통계량
$$F = \dfrac{MS_B}{MS_E}$$
여기서, $F$는 F분포를 나타내는 확률변수
가설검정
귀무가설일 때 검정통계량($F_0$)은 집단간분산($MS_{B}$)의 집단내분산($MS_W$)에 대한 상대적 크기를 나타내는데, 기준이 되는 집단내분산($MS_W$)이 다음의 모집단 모델에서는 오차항인 $\epsilon_{ij}$로 표현됩니다.
$$y_{ij}=\mu+\alpha_i+\epsilon_{ij}$$
여기서, $y_{ij}$는 $i$번째 집단의 $j$번째의 관찰값
$\mu$는 전체 평균
$\alpha_i$는 $i$번째 그룹(집단)의 효과: 그룹(집단) 평균에서 전체 평균과의 차이
$\epsilon_{ij}$는 오차항이며 $i$번째 그룹의 $j$번째 오차: 정규분포를 따르는 독립적인 확률변수
집단의 평균으로 모집단 모델을 식으로 표현하면 다음과 같습니다.
$$y_{ij}=\mu_i+\epsilon_{ij}$$
여기서, $y_{ij}$는 $i$번째 집단의 $j$번째의 관찰값
$\mu_i$는 $i$번째 집단의 평균: $\mu_i=\mu+\alpha_i$
$\epsilon_{ij}$는 오차항이며 $i$번째 그룹의 $j$번째 오차: 정규분포를 따르는 독립적인 확률변수
집단의 분산에 대한 등분산성과 오차항으로 표현하는 개체의 정규성과 독립동일분포(independent identical distribution) 가정이 성립할 때 다음과 같이 가설을 세우고 가설에 대한 검정을 진행할 수 있습니다.
귀무가설
귀무가설: 각 집단(그룹)의 다름에 의한 효과는 없다. $\rightarrow$ 효과는 0이다.
$$H_{0}: \alpha_{1}=\alpha_{2}=\cdots=\alpha_{k}=0$$
귀무가설: 각 집단(그룹)의 평균은 같다. $\rightarrow$ 집단의 평균은 전체평균과 같다.
$$H_{0}: \mu_{1}=\mu_{2}=\cdots=\mu_{k}=\mu$$
대립가설
대립가설($H_{1}$): 적어도 한 $\alpha_{k}$는 0이 아니다.
대립가설($H_{1}$): 모든 집단에서 적어도 한 집단의 평균은 전체평균과 다르다.
검정통계량
$$F_{0}=\dfrac{\dfrac{SS_{B}}{k-1}}{\dfrac{SS_W}{n-k}}=\dfrac{MS_{B}}{MS_W}$$
기각역
유의수준 $\alpha$인 검정에서, 계산된 $F_{0}$의 값이 $F$분포에서 구한 값 $F_{k-1,n-k;\alpha{}}$보다 크면 $MS_{B}$가 $MS_W$보다 충분히 크다고 판정하여 귀무가설 $H_{0}$를 기각하게 됩니다. 즉, 각 집단의 평균이 같지 않다고 판정합니다.
$F_{0}>F_{k-1,n-k;\alpha{}}$ 이면 $H_{0}$ 를 기각
여기서, $F$분포의 모수인 분자, 분모의 자유도는 $(k-1)$, $(n-k)$
사후검정
$$HSD_{ij}=q_{k,n-k;\alpha}\cdot\sqrt{\frac{1}{2}(\frac{1}{n_i}+\frac{1}{n_j})MS_{W}}$$
일원분산분석 F검정표
| 귀무가설$(H_0)$ | 검정통계량 | 대립가설$(H_1)$ | 귀무가설 기각역 |
$\alpha_1=\alpha_2=\cdots=\alpha_k=0$ 여기서, $\alpha_i$는 $i$번째 집단의 효과
$$\mu=\mu_{1}=\mu_{2}=\cdots=\mu_{k}$$ 여기서, $\mu$는 전체 집단의 평균 $\mu_i$는 $i$번째 집단의 평균 | $F_0=\dfrac{MS_{B}}{MS_W}$ | 적어도 한 $\alpha_k$는 $0$보다 크다. | 검정통계량으로 $\alpha_k$가 0보다 큰지 알 수 없다. |
| 적어도 한 $\alpha_k$는 $0$보다 작다. | 검정통계량으로 $\alpha_k$가 0보다 작은지 알 수 없다. | ||
| 적어도 한 $\alpha_k$는 $0$이 아니다. | $F_0>F_{k-1,n-k;\alpha}$ |
t검정과 F검정 비교
t검정결과에서 F검정결과 유도
두 집단 모평균 비교시 $t$검정과 $F$검정의 결과는 동일합니다 . $t$검정식에서 $F$검정식을 유도하여 두 검정의 결과가 동일함을 증명합니다. 즉, 두 확률변수, $t_{\nu}^2$와 $F_{1, \nu}$가 같음을 다음과 같이 증명합니다.
검정통계량
$$\eqalign{t^2&=\dfrac {\left(\bar{X}_2-\bar{X}_1\right)^2}{\dfrac {S_p^2}{n_1}+\dfrac {S_p^2}{n_2}} \cr &= \dfrac{\left(\bar{X}_2-\bar{X}_1\right)^2 \left(\dfrac{n_1 n_2}{n_1+n_2}\right)}{S_p^2}\cr &= \dfrac{\bar {D}^2 \left(\dfrac{n_1 n_2}{n_1+n_2}\right)}{S_p^2}}$$
집단내변동의 자유도
$$\nu_W = \nu = \nu_1 + \nu_2 = (n_1 -1)+(n_2 -1)=n_1 + n_2 -2=n-2$$
집단간변동의 자유도
$$\nu_{B} = 1$$
집단내분산($MS_W$)=통합분산($s_p^2$)
$$S_p^2=MS_W=\dfrac{\left(X_{11} – \bar {X}_1\right)^2+ \cdots + \left(X_{n11} – \bar {X}_1\right)^2 + \left(X_{12} – \bar {X}_2\right)^2 + \cdots +\left(X_{n22} – \bar {X}_2\right)^2}{n_1 + n_2 – 2}$$
집단간분산($MS_{B}$)
$$\eqalign {MS_{B}&=n_1 \left(\bar{X}_1 – \bar{X}\right)^2 + n_2 \left(\bar{X}_2 – \bar{X}\right)^2 \cr &=n_1 \left(\bar{X}_1 – \dfrac{n_1 \bar{X}_1 + n_2 \bar{X}_2}{n_1 +n_2}\right)^2 + n_2 \left(\bar{X}_2 – \dfrac{n_1 \bar{X}_1 + n_2 \bar{X}_2}{n_1 +n_2}\right)^2 \cr &=n_1 \left(\dfrac{n_1 \bar{X}_1 + n_2 \bar{X}_2 – n_1 \bar{X}_1 – n_2 \bar{X}_2}{n_1 +n_2}\right)^2 + n_2 \left(\dfrac{n_1 \bar{X}_2 + n_2 \bar{X}_2 – n_1 \bar{X}_1 – n_2 \bar{X}_2}{n_1 +n_2}\right)^2 \cr &=n_1 \left(\dfrac{n_2 \bar{X}_1 – n_2 \bar{X}_2}{n_1 +n_2}\right)^2 + n_2 \left(\dfrac{n_1 \bar{X}_2 – n_1 \bar{X}_1}{n_1 +n_2}\right)^2 \cr &= \left(\dfrac {\bar{X}_1 – \bar{X}_2}{n_1 +n_2}\right)^2 \left(n_1 n_2^2 + n_2 n_1^2\right) \cr &= \dfrac {\left(\bar{X}_1 – \bar{X}_2\right)^2}{\left(n_1 + n_2\right)^2} \left(n_1 n_2\right)\left(n_1 + n_2\right)\cr &= \dfrac {\left(\bar{X}_1 – \bar{X}_2\right)^2} {n_1 + n_2} n_1 n_2 \cr &= \left(\bar{X}_1 – \bar{X}_2\right)^2 \left(\dfrac{n_1 n_2}{n_1 + n_2}\right) \cr &=\bar D^2\left(\dfrac{n_1 n_2}{n_1 + n_2}\right)}$$
두 집단 평균차이, $\bar D$의 $Z$변환
$$\eqalign{Z_\bar{D} &= \dfrac{\bar{D}}{SE\left(\bar{D}\right)} \cr &= \dfrac{\bar{D}}{\sigma_{\bar{D}}} \cr &= \dfrac{\bar{D}}{\sigma \sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}}$$
왜냐하면
$$\because \sigma_{\bar{D}} = \sqrt{\dfrac{\sigma_1^2}{n_1}+\dfrac{\sigma_2^2}{n_2}} = \sigma\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}$$
왜냐하면
$$\because \sigma^2 = \sigma_1^2 = \sigma_2^2$$
왜냐하면
$$\because H_0 : \mu_1 – \mu_2 = \bar{X}_2 – \bar{X}_1 = 0$$
$Z_{\bar D}$의 $t$변환
$$t_{\nu} \equiv \dfrac{Z_{\bar{D}}}{\sqrt{\dfrac{V}{\nu}}} = \dfrac{\bar{D}}{\sigma\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}\sqrt{\dfrac{V}{\nu}}}$$
$t_{\nu}^2=F_{\nu_{B}, \nu_W}$ 증명
$$\eqalign{t_{\nu}^2 &= \dfrac{Z_{\bar{D}}^2}{\dfrac{V}{\nu}}\cr &=\dfrac{\dfrac{\bar{D}^2}{\sigma^2}\left(\dfrac{\nu}{V}\right)}{\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)} \cr &\sim \dfrac{\dfrac{\bar{D}^2}{S_p^2}}{\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}\cr &= \dfrac{\bar{D}^2}{\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)} \dfrac{1}{MS_W} \cr &= \dfrac{MS_{B}}{MS_W} \cr &= F_{\nu_{B} , \nu_W}}$$
왜냐하면
$$\because V= \chi_\nu^2 = \dfrac{\left(\nu_1 S_1^2 + \nu_2 S_2^2 \right)}{\sigma^2} \sim \dfrac{\nu S_p^2}{\sigma^2}$$
왜냐하면
$$\because S_p^2 \equiv \dfrac{\left(\nu_1 S_1^2+\nu_2 S_2^2\right)}{\nu}$$
집단간분산($MS_{B}$)
$$MS_{B} = \dfrac{\bar{D}^2}{\dfrac{1}{n_1}+\dfrac{1}{n_2}} = \dfrac{\left(\bar{X}_1-\bar{X}\right)^2 n_1+\left(\bar{X}_2-\bar{X}\right)^2 n_2}{\nu_{B}}$$
집단간변동의 자유도
$$\nu_{B} = 1$$
새로운 확률변수 $F$
$$\dfrac{MS_{B}}{MS_W} = F_{\nu_{B},\nu_W} = F_{1,\nu_W}$$
따라서
$$\therefore t_{\nu}^2 = F_{1,\nu_W} = F_{1,\nu}$$
$SS_{W}$와 $MS_{W}$
$$\eqalign{SS_W &= \left(X_{11}-\bar{X}_1\right)^2+\cdots+\left(X_{n_1 1}-\bar{X}_1\right)^2+\left(X_{12}-\bar{X}_2\right)^2+\cdots+\left(X_{n_2 2}-\bar{X}_2\right)^2 \cr &= \left(n_1 – 1\right)\dfrac{\left(X_{11}-\bar{X}_1\right)^2+\cdots+\left(X_{n_1 1}-\bar{X}_1\right)^2}{\left(n_1 – 1\right)}+\left(n_2 – 1\right)\dfrac{\left(X_{12}-\bar{X}_2\right)^2+\cdots+\left(X_{n_2 2}-\bar{X}_2\right)^2}{\left(n_2 – 1\right)}\cr &= \left(n_1 – 1\right)s_1^2+\left(n_2 – 1\right)s_2^2}$$
따라서
$$\therefore MS_W = \dfrac{\left(n_1 – 1\right)S_1^2 + \left(n_2 – 1\right)s_2^2}{\left(n_1 + n_2 -2\right)} = s_p^2$$
F검정결과에서 t검정결과 유도
두 집단 모평균 비교시 $t$검정과 $F$검정의 결과는 동일합니다 . $t$검정식에서 $F$검정식을 유도하여 두 검정의 결과가 동일함을 증명합니다. 즉, 두 확률변수, $t_{\nu}^2$와 $F_{1, \nu}$가 같음을 다음과 같이 증명합니다.
확률변수
$$\bar{D}^2 = \left(\bar{X}_2 – \bar{X}_1\right)^2$$
$$\nu_{B} = 1$$
$$\nu_W = \nu = \left(n_1 + n_2 – 2\right)$$
등분산가정
$$\sigma^2 = \sigma_1^2 = \sigma_2^2$$
귀무가설
$$H_o : \mu_2 -\mu_1 = \bar{X}_2 – \bar{X}_1 = 0$$
증명
$$\eqalign{F_{1,\nu} &= F_{1, \nu_W} \Longleftarrow \nu = \nu_W = \left(n_1 + n_2 – 2\right) \cr &= \dfrac{MS_{B}}{MS_W} \cr &= \dfrac{\dfrac{\bar{D}^2 n_1 n_2}{n_1 + n_2}}{S_p^2} \cr &= \dfrac{\dfrac{\left(\bar{X}_2 – \bar{X}_1\right)^2 n_1 n_2}{n_1 + n_2}}{s_p^2} \cr &= \dfrac{\left(\bar{X}_2 – \bar{X}_1\right)^2}{\dfrac{s_p^2}{n_1}+\dfrac{s_p^2}{n_2}} \cr &= t_\nu^2 }$$
집단내변동($SS_W$)
$$\eqalign{SS_W &= \left(\left(X_{1_1} – \bar{X}_1\right)^2+\cdots+\left(X_{{n1}_1} – \bar{X}_1\right)^2\right)+\left(\left(X_{1_2} – \bar{X}_2\right)^2+\cdots+\left(X_{{n2}_2} – \bar{X}_2\right)^2\right) \cr &= \dfrac{\left(n_1 – 1\right)\left(\left(X_{1_1} – \bar{X}_1\right)^2+\cdots+\left(X_{{n1}_1} – \bar{X}_1\right)^2\right)}{n_1 -1} + \dfrac{\left(n_2 – 1\right)\left(\left(X_{1_2} – \bar{X}_2\right)^2+\cdots+\left(X_{{n2}_2} – \bar{X}_2\right)^2\right)}{n_1 -1} \cr &= \left(n_1 – 1\right)S_1^2 + \left(n_2 – 1\right)S_2^2 }$$
집단내분산($MS_W$) = 통합표본분산($s_p^2$)
$$\eqalign{MS_W &= \dfrac{SS_W}{\nu_W} \Longleftarrow \nu = \nu_W = \left(n_1 + n_2 – 2\right) \cr &= \dfrac{\left(n_1 -1\right)S_1^2 + \left(n_2 -1\right)S_2^2}{n_1 + n_2 -2} \Longleftarrow \ \sigma^2 = \sigma_1^2 = \sigma_2^2 \sim \sigma_p^2 \cr &= s_p^2 \cr } $$
집단간변동($SS_{B}$)
$$SS_{B} = n_1 \left(\bar{X}_1 – \bar{X}\right)^2 + n_2 \left(\bar{X}_2 – \bar{X}\right)^2$$
집단간분산($MS_{B}$)
$$\eqalign{ MS_{B} &= \dfrac{SS_{B}}{\nu_{B}} \cr &= \dfrac{n_1\left(\bar{X}_1 – \bar{X}\right)^2 + n_2\left(\bar{X}_2 – \bar{X}\right)^2}{\nu_{B}} \Longleftarrow \nu_{B} = 1 \cr &= n_1\left(\bar{X}_1 – \bar{X}\right)^2 + n_2\left(\bar{X}_2 – \bar{X}\right)^2 \Longleftarrow \bar{X} = \dfrac{\bar{X}_1 n_1 + \bar{X}_2 n_2}{n_1 + n_2} \cr &= n_1\left(\dfrac{\bar{X}_1 – \left(n_1\bar{X}_1 + n_2\bar{X}_2\right)}{n_1 + n_2}\right)^2 + n_2\left(\dfrac{\bar{X}_2 – \left(n_1\bar{X}_1 + n_2\bar{X}_2\right)}{n_1 + n_2}\right)^2 \cr &= n_1\left(\dfrac{n_1\bar{X}_1 + n_2\bar{X}_1 – n_1\bar{X}_1 – n_2\bar{X}_2}{n_1 + n_2}\right)^2 + n_2\left(\dfrac{n_1\bar{X}_2 + n_2\bar{X}_2 – n_1\bar{X}_1 – n_2\bar{X}_2}{n_1 + n_2}\right)^2 \cr &= n_1\left(\dfrac{n_2\bar{X}_1 – n_2\bar{X}_2}{n_1 + n_2} \right)^2 + n_2\left(\dfrac{n_1\bar{X}_2 – n_1\bar{X}_1}{n_1 + n_2}\right)^2 \cr &= \left(\dfrac{\bar{X}_1 – \bar{X}_2}{n_1 + n_2}\right)^2 \left(n_1 n_2^2 + n_2 n_1^2\right) \cr &= \dfrac{\left(\bar{X}_1 – \bar{X}_2\right)^2}{\left(n_1 + n_2\right)^2} n_1 n_2 \left(n_1 + n_2\right) \cr &= \dfrac{\left(\bar{X}_1 – \bar{X}_2\right)^2 n_1 n_2}{n_1 + n_2} \cr &= \bar{D}^2\dfrac{ n_1 n_2}{n_1 + n_2} \cr }$$
Terminology
분산분석(analysis of variance: ANOVA)
분산분석(Analysis of variance: ANOVA)은 표본내의 집단 평균 간의 차이를 분석하는 데 사용되는 통계모델 및 관련 추정 절차 (예 : 집단 간 및 집단 내 “변동”)의 모음입니다. 분산분석은 통계학자이자 진화생물학자 Ronald Fisher가 개발했습니다. ANOVA는 특정 변수의 관찰된 분산이 다양한 변동 요인에 기인하는 구성 요소의 분산으로 분할되는 전체 분산의 법칙(the law of total variance)에 기반합니다. 가장 단순한 형태로 ANOVA는 두 개 이상의 모집단 평균이 같은지에 대한 통계적 검정(statistical test)을 제공하므로 두 평균을 검정하는 $t$검정을 일반화한 것으로 볼 수 있습니다.
출처
Reference
본인의 Google 계정으로 구글시트를 복사
=AVERAGE(C3:C22) : 평균. C3에서 C22에 있는 모든 데이터의 산술평균.
=VAR.S(C3:C22) : 표본분산. C3에서 C22에 있는 모든 데이터의 표본분산. 각 값과 산술평균과의 차이 제곱을 모두 더한 후, 데이터 개수-1(n-1)로 나눈 값.
=값 혹은 셀^2 : 제곱.
=SUM(J3:J62) : 합. J3에서 J62에 있는 모든 데이터의 합.
=COUNTUNIQUE(B3:B62) : 데이터 개수. B3에서 B62에 있는 데이터 중 중복되지 않는 데이터 개수.
=COUNT(A3:A62) : 데이터 개수. A3에서 A62에 있는 모든 숫자 데이터의 개수.
=F.DIST.RT(Q3,O3,O4) : 확률밀도. O3와 O4를 자유도로 가지는 F분포 상에서 Q3 우측의 확률밀도를 적분한 값.
=F.INV.RT(U3,O3,O4) : 확률밀도함수의 역함수. O3와 O4를 자유도로 가지는 F분포 상에서 어떤 값을 기준으로 우측의 확률밀도를 적분한 값이 U3가 되는 어떤 값.
=IF(T3>V3,“YES”,“NO”) : 조건문. T3가 V3보다 크면 YES를 표시하고, 그렇지 않으면 NO를 표시함.
=F.DIST(Y3,O3,O4,FALSE) : 확률밀도. O3와 O4를 자유도로 가지는 F분포 상에서 Y3 값이 가지는 확률밀도. FALSE를 TRUE로 변경하면, 누적확률밀도를 계산함.