지역은 한우가 자란 물리적인 공간을 나타내는 범주의 이름이며 서로 배타적입니다. 집합으로 설명하면, A, B, C는 지역이라는 집합의 부분집합입니다. 따라서 지역은 범주형변수의 이름으로, A, B, C는 범주형변수의 값(데이터)으로 모델링합니다. A, B, C는 지역을 관측한 결과인 범주형데이터입니다.
한우의 개량은 국가개량사업에서 후대검정(progeny testing) 방법을 이용하여 보증 씨수소를 선발하여 전국 농가에 우량 씨수소의 정액(semen)을 보급하고 있고, 각 지자체별로 암소의 유전적 개량을 진행하고 있다. 암소의 유전적 개량의 주요 목표형질은 도체중(carcass weight), 등심단면적(Eye muscle area), 등지방두께(backfat thickness) 및 근내지방도(marbling score)이다. 국내 각 지자체의 암소개량의 의지에 따라서 지자체(지역)별로 암소의 유전능력이 서로 상이하게 다를 것이다. 따라서, 본 연구프로젝트에서는 각 지자체(지역)별로 개량의 목표형질인 도체중(carcass weight, kg)이 다른지 알아보는 프로젝트를 진행하였다. 한우 100마리를 표본으로 하고, 도체중을 확률변수로 하였다. 지역이 다른 한우 100마리를 비교해서 한우는 지역에 따라 도체중이 다르다를 검정하였다. 집단간/집단내분산의 비를 일원분산분석 F검정으로 검정한 결과, 유의미한 차이를 보였다.(p=0.01) 이번 프로젝트를 통해 한우는 지역에 따라 도체중이 다르다고 할 수 있다.
Key Word
한우, 도체중, 지역, 일원분산분석, F검정
서론
한우의 개량은 국가개량사업에서 후대검정(progeny testing) 방법을 이용하여 보증 씨수소를 선발하여 전국 농가에 우량 씨수소의 정액(semen)을 보급하고 있고, 각 지자체별로 암소의 유전적 개량을 진행하고 있다. 따라서 지자체(지역)별로 암소의 유전능력이 서로 다를 것이다. 더욱이 우리나라에는 다양한 지역에 다양한 사육방법으로 한우를 생산하는 브랜드들이 존재한다. 이러한 암소의 유전능력의 차이 및 브랜드들의 소 사육방식에 따라서 한우의 도체중이 얼마나 다른지를 검정하였다.
모델링
가설
한우는 지역에 따라 도체중이 다르다라는 연구주제로부터, 지역에 따라 분류한 한우의 도체중 모평균과 전체 한우의 도체중 모평균 차이는 0이다라는 귀무가설을 도출하고, 이 가설을 반증하는 지역에 따라 분류한 한우의 도체중 모평균 중 적어도 하나는 전체 한우의 도체중 모평균과 다르다라는 대립가설을 도출한다.
확률변수
도체중(kg)을 확률변수로 한다. 도체중은 한우 도체의 무게로 kg(킬로그램) 단위로 표시한다.
실험설계
한우100마리의 지역과 도체중을 관측하였다. 우리나라에는 다양한 지역에 다양한 방법으로 한우를 생산하는 브랜드들이 있다. 즉, 지역간 브랜드를 통해서 차별성있는 한우를 생산한다고 말할 수 있다. 지역별 한우 씨수소 선발시 도체중을 중시하는 지역이 있고, 근내지방을 선호하는 지역이 존재하여 지역별 도체중의 차이가 있을 수 있다.
데이터
데이터수집
한우100마리의 지역과 도체중을 표로 정리하였다.
Table 1. 한우의 지역별 도체중
한우 ID
지역
도체중 (kg)
1
A
466
2
A
406
3
A
428
4
A
493
5
A
460
6
A
498
7
A
461
8
A
405
9
A
404
10
A
511
11
A
355
12
A
482
13
A
428
14
A
435
15
A
468
16
A
442
17
A
502
18
A
422
19
A
435
20
A
411
21
A
494
22
A
380
23
A
340
24
A
532
25
A
549
26
A
445
27
A
429
28
B
425
29
B
421
30
B
392
31
B
423
32
B
429
33
B
418
34
B
368
35
B
357
36
B
361
37
B
497
38
B
445
39
B
353
40
B
401
41
B
459
42
B
459
43
B
441
44
B
447
45
B
353
46
B
420
47
B
346
48
B
381
49
B
449
50
B
359
51
B
379
52
B
444
53
B
463
54
B
427
55
B
462
56
B
359
57
B
440
58
B
365
59
B
493
60
B
406
61
B
372
62
B
412
63
B
390
64
B
458
65
B
434
66
B
450
67
B
414
68
B
507
69
B
346
70
B
385
71
B
469
72
B
370
73
B
476
74
B
433
75
B
387
76
B
504
77
B
422
78
B
370
79
B
390
80
B
379
81
B
448
82
B
425
83
B
346
84
B
416
85
C
420
86
C
421
87
C
466
88
C
532
89
C
412
90
C
382
91
C
416
92
C
461
93
C
448
94
C
435
95
C
394
96
C
379
97
C
419
98
C
442
99
C
385
100
C
382
데이터시각화
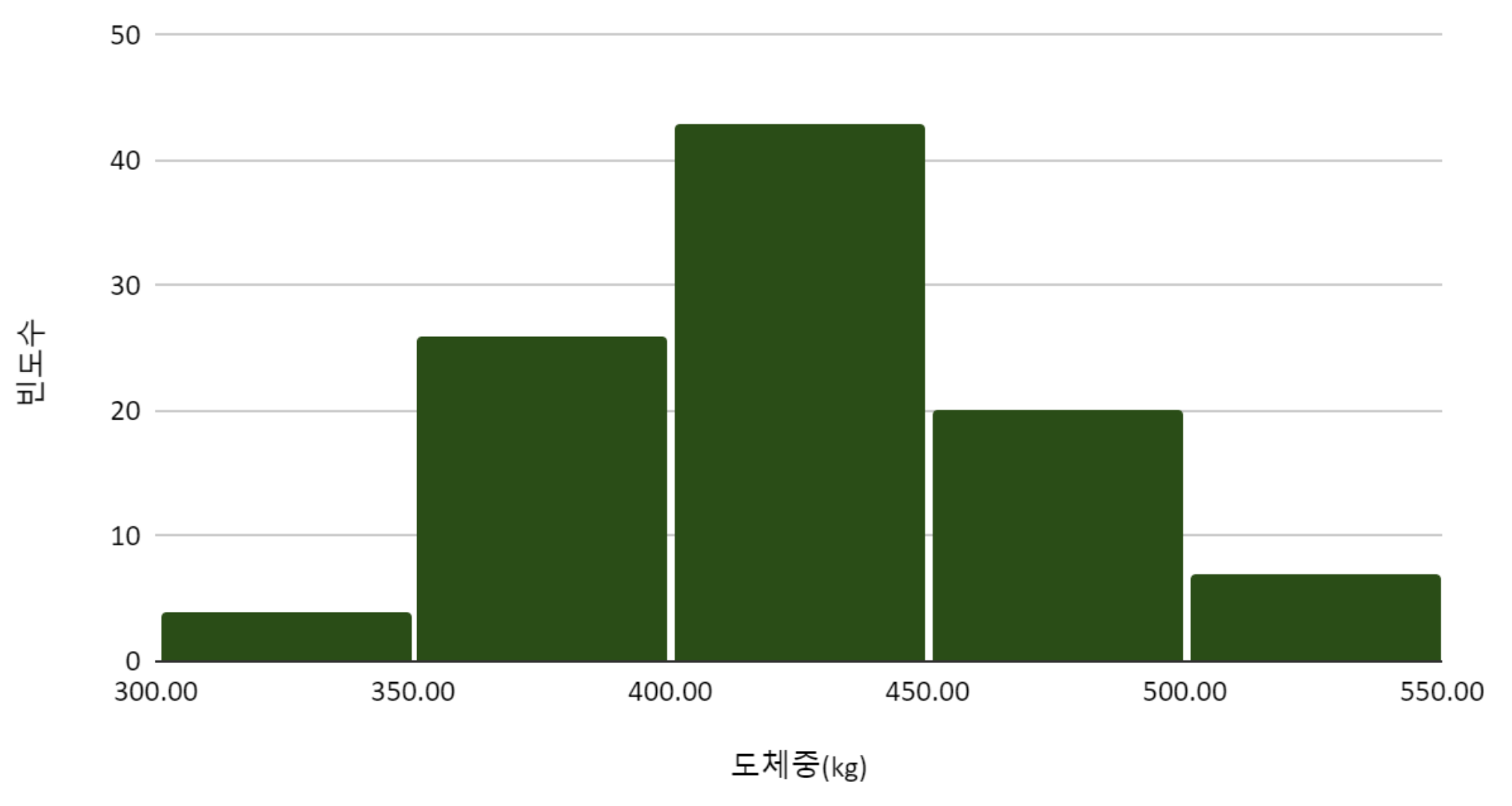
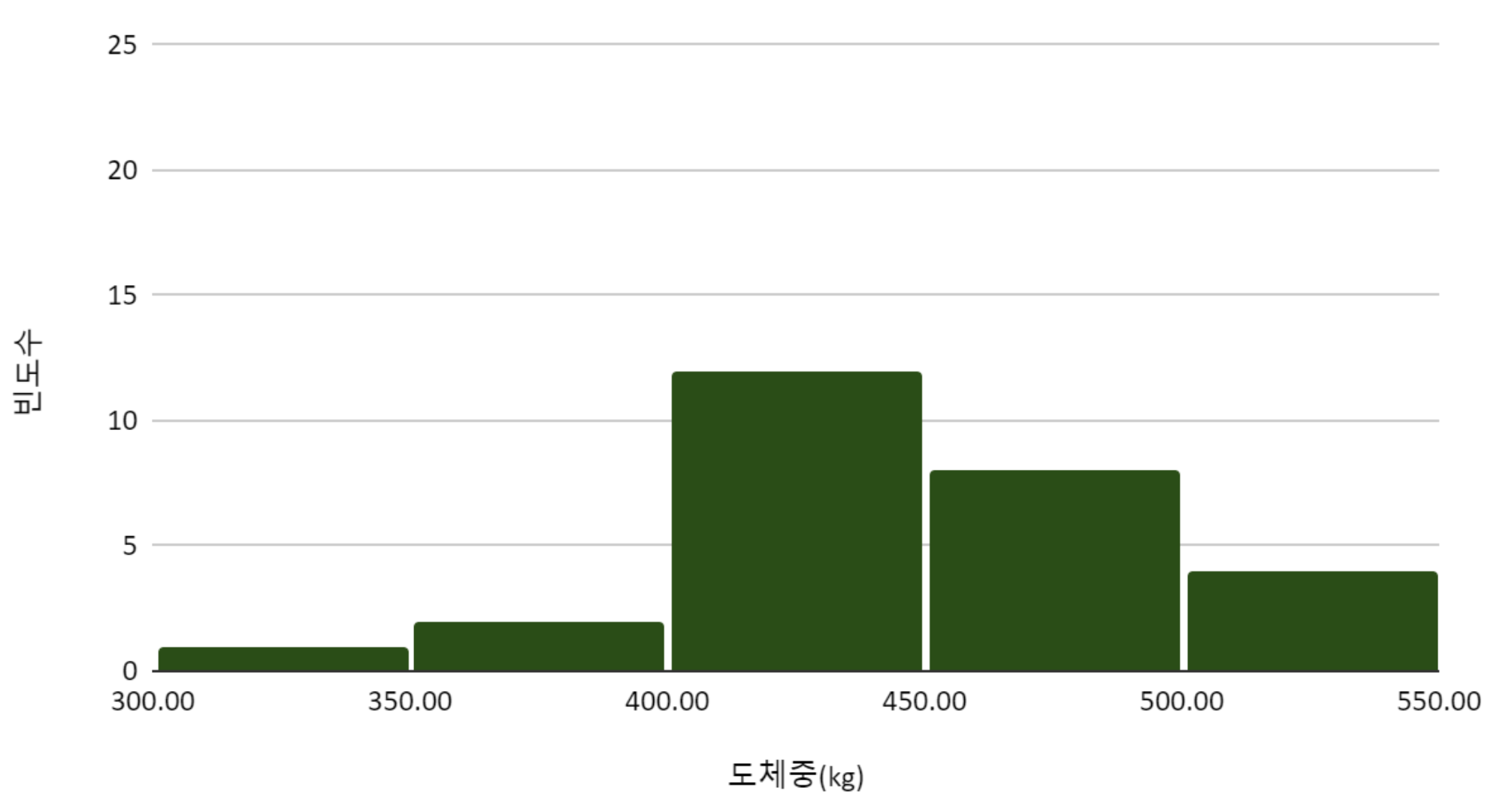
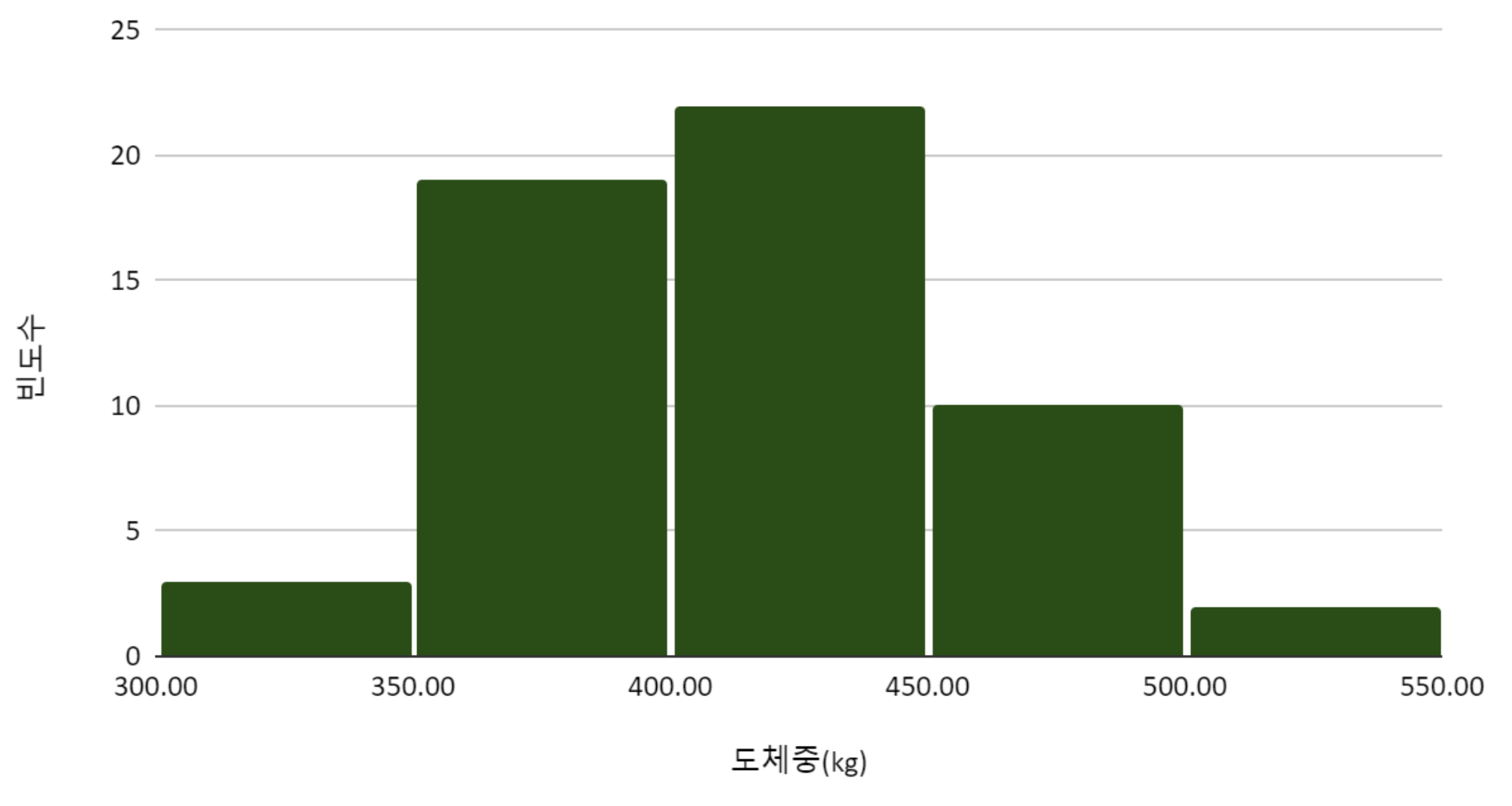
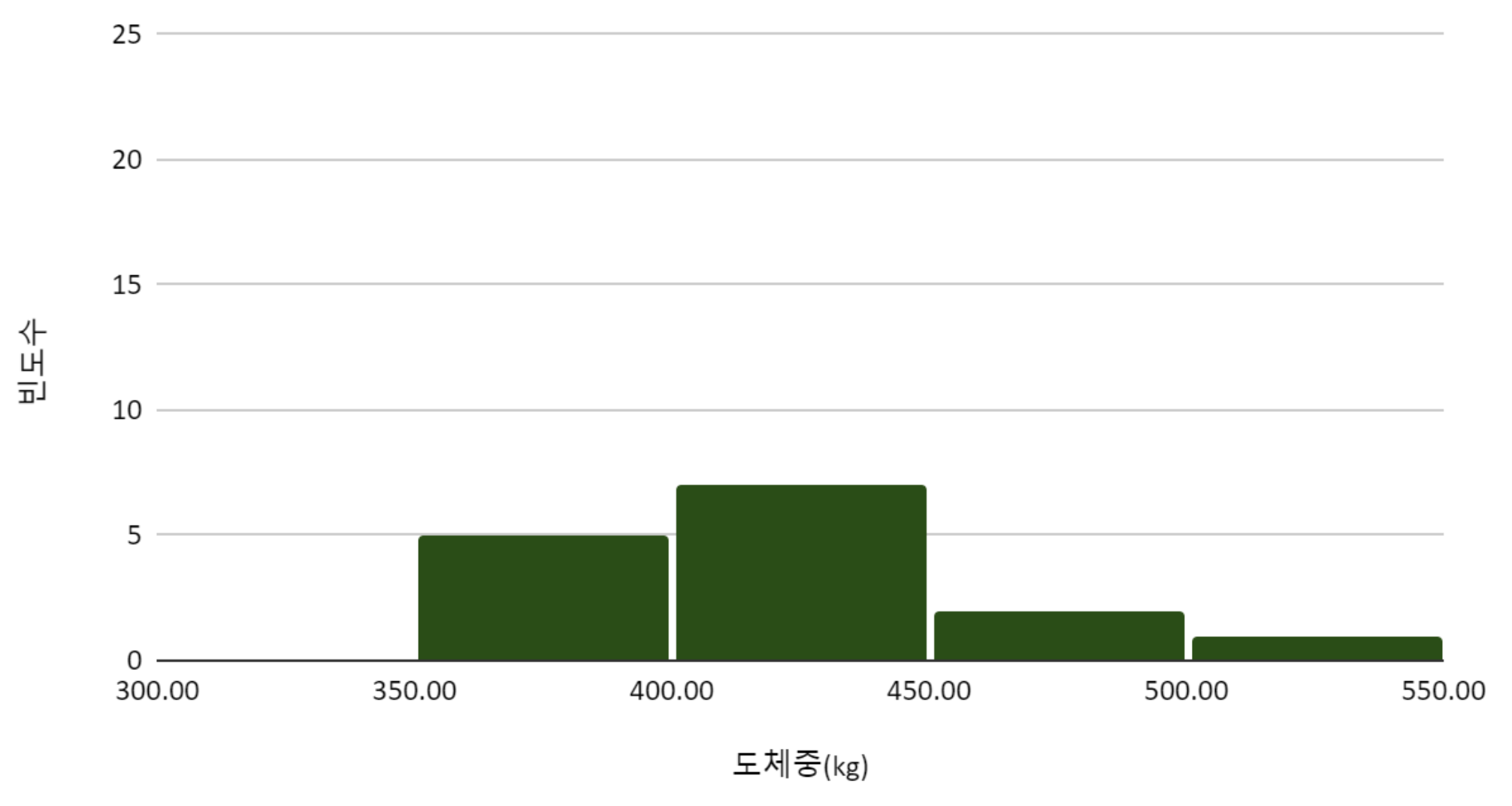
히스토그램를 그려서, 지역 별 도체중 분포를 탐색하였다.
Figure 1. 한우의 도체중 분포
Figure 2. A지역 한우의 도체중 분포
Figure 3. B지역 한우의 도체중 분포
Figure 4. C지역 한우의 도체중 분포
데이터분석
가설검정
연구주제 : 한우는 지역에 따라 도체중이 다르다
귀무가설 : 지역에 따라 분류한 한우의 도체중 모평균과 전체 한우의 도체중 모평균 차이는 0이다
귀무가설이 옳다면, 집단간분산과 집단내분산의 비는 확률변수로 확률분포를 F분포로 가설검정할 수 있다.
표본을 통해 관측한 검정통계량은 4.76이며, 유의확률은 0.01
만일 유의수준을 0.05로 하면, 유의확률이 유의수준보다 작으므로, 귀무가설 기각
귀무가설이 기각되었으므로 대립가설 채택
검정결과
집단간분산과 집단내분산의 비를 일원분산분석 F검정으로 검정한 결과, 지역별 한우 도체중 평균이 유의미한 차이를 보였다.(p=0.01) 한우는 지역에 따라 도체중이 다르다고 할 수 있다.
Table 2. 지역별 한우 도체중 평균 비교 : 일원분산분석 F검정
분산구분
제곱합
자유도
평균제곱
검정통계량
유의확률
집단간
19501.34
2
9750.67
4.76
0.01
집단내
198722.66
97
2048.69
Total
218224.00
99
결론
집단간분산과 집단내분산의 비를 일원분산분석 F검정으로 검정한 결과, 지역별 한우 도체중 평균이 유의미한 차이를 보였다.(p=0.01) 한우는 지역에 따라 도체중이 다르다고 할 수 있다.
참고문헌
Bhuiyan, et al. 2016. M.S.A.Bhuiyan, D.H.Lee, H.J.Kim, S.H.Lee, S.H.Cho, B.S.Yang, S.D.Kim, S.H.Lee. Estimates of genetic parameters for fatty acid compositions in the longissimus dorsi muscle of Hanwoo cattle. Animal, 12 (2018), pp. 675-683
본인의 Google 계정으로 구글시트를 복사
=AVERAGE(C3:C22) : 평균. C3에서 C22에 있는 모든 데이터의 산술평균.
=VAR.S(C3:C22) : 표본분산. C3에서 C22에 있는 모든 데이터의 표본분산. 각 값과 산술평균과의 차이 제곱을 모두 더한 후, 데이터 개수-1(n-1)로 나눈 값.
=값 혹은 셀^2 : 제곱.
=SUM(J3:J62) : 합. J3에서 J62에 있는 모든 데이터의 합.
=COUNTUNIQUE(B3:B62) : 데이터 개수. B3에서 B62에 있는 데이터 중 중복되지 않는 데이터 개수.
=COUNT(A3:A62) : 데이터 개수. A3에서 A62에 있는 모든 숫자 데이터의 개수.
=F.DIST.RT(Q3,O3,O4) : 확률밀도. O3와 O4를 자유도로 가지는 F분포 상에서 Q3 우측의 확률밀도를 적분한 값.
=F.INV.RT(U3,O3,O4) : 확률밀도함수의 역함수. O3와 O4를 자유도로 가지는 F분포 상에서 어떤 값을 기준으로 우측의 확률밀도를 적분한 값이 U3가 되는 어떤 값.
=IF(T3>V3,“YES”,“NO”) : 조건문. T3가 V3보다 크면 YES를 표시하고, 그렇지 않으면 NO를 표시함.
=F.DIST(Y3,O3,O4,FALSE) : 확률밀도. O3와 O4를 자유도로 가지는 F분포 상에서 Y3 값이 가지는 확률밀도. FALSE를 TRUE로 변경하면, 누적확률밀도를 계산함.