[DATA SCIENCE]
데이터사이언스 > 모델링 > 연구설계 > 검정
모수검정과 비모수검정
[Q&A]
새로운 확률변수는 무엇
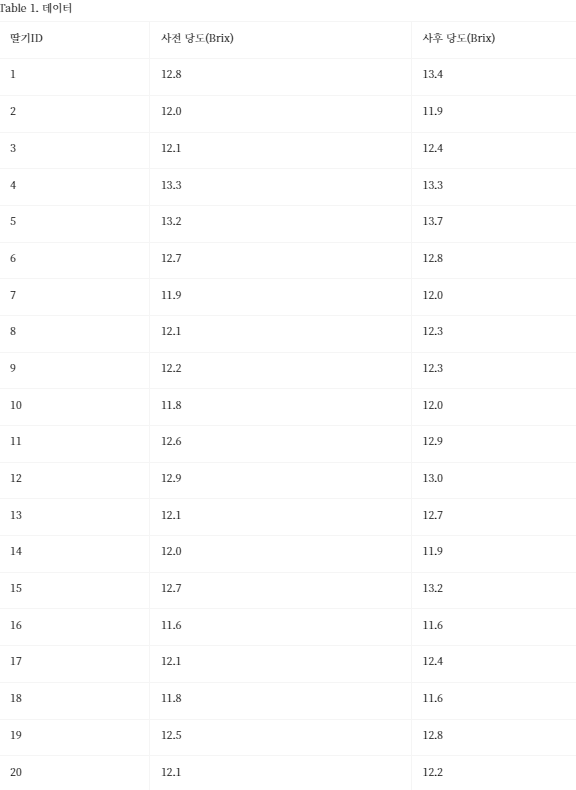
초등학생의 보드게임 사전과 사후의 수학적 창의력 점수 차이입니다.
귀무가설은 기준을 생성하는가
절대 0이 없는 간격척도로 구한 데이터를 비교할 수 있게 해줍니다.
차이평균의 귀무가설과 원점의 관계는
귀무가설에서의 “0”은 두 모집단의 평균 차이가 없음을 나타내며, 이는 통계적으로 “원점” 또는 “기준점”으로 간주합니다.
대응표본과 독립표본에서 새로운 확률변수를 확률변수값의 차이라고 할 때 어느 표본의 분산이 더 큰가
일반적으로 독립표본에서의 새로운 확률변수의 분산이 대응표본에서의 새로운 확률변수의 분산보다 더 크다고 할 수 있습니다. 이는 독립표본의 경우 두 모집단의 변동성이 모두 분산에 기여하기 때문입니다.
표준편차는 단위가 될 수 있는가
표준편차의 단위는 데이터의 원 단위를 유지하기 때문에, 그것을 데이터 집합의 변동성을 나타내는 ‘단위’로 사용할 수 있습니다. 결론적으로, 표준편차를 단위로 사용하는 것은 엄밀히 말하면 정확하지 않지만, 특정 상황에서는 유용하게 활용될 수 있습니다. 사용 전에 주의 사항을 숙지하고, 필요에 따라 다른 방법을 함께 사용하는 것이 바람직합니다.
대응표본과 독립표본은 무엇이 다른가
독립표본은 독립된 두개 이상의 범주를 가집니다. 대응표본은 개체로 연결되어 있으며 같은 시간이나 공간의 이동으로 같은 개체의 속성변동을 반영합니다.
ARTICLE CONTENTS
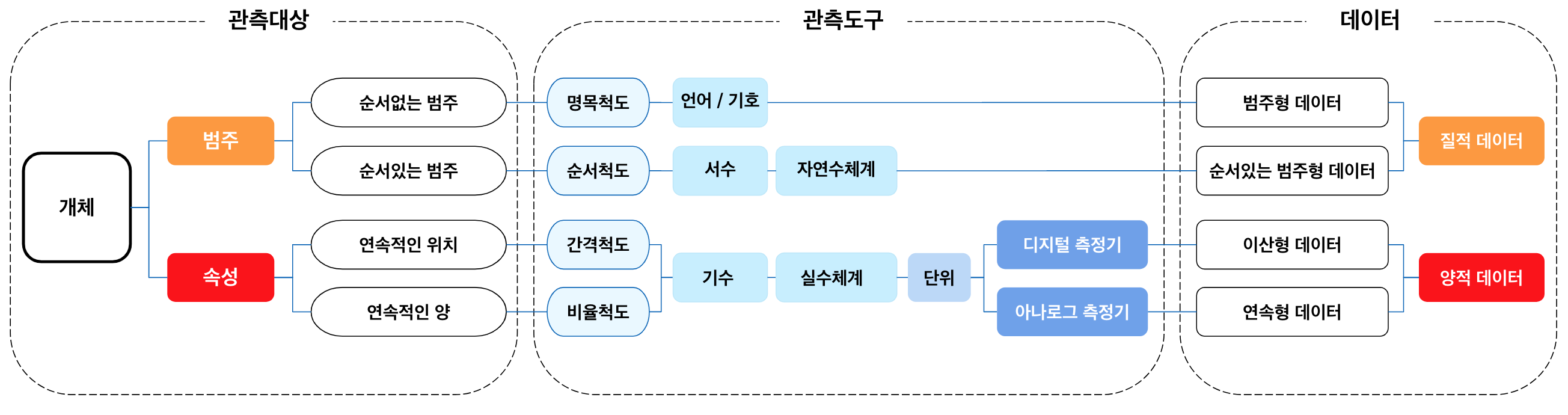
데이터종류
0:17Data & Code
1:09Parametric test and non-parametric test
Author
박근철![]() , 양윤원
, 양윤원![]()
DocuHut Co. Ltd., Seoul, Republic of Korea
Citation
Park GC, Yang YW. Data Type. Data Science 2024;1:1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
가설에 대한 검정에는 모집단이 정규분포를 따를 때 적용되는 모수검정과 정규분포를 따르지 않는 경우에 적용되는 비모수검정에 대해 설명합니다. 모수검정은 모집단의 평균과 분산이 알려진 정규분포를 기반으로 하며, 표본평균과 표본분산을 통해 새로운 확률변수를 정의하고 이를 통해 가설을 검정합니다. 특히, 표본평균과 표본분산을 변환하여 얻어진 확률변수들은 표준정규분포, 카이제곱분포, t분포, F분포 등을 따르게 됩니다. 이러한 과정은 정규분포를 가정할 수 있는 모집단으로부터 얻은 표본에 기반한 모수의 추정과 가설검정을 가능하게 합니다.
반면, 비모수검정은 모집단의 분포가 정규분포가 아니거나, 데이터가 순서척도 또는 명목척도로 측정되었거나, 데이터의 수가 적은 경우에 필요합니다. 비모수검정은 모수검정에 비해 검정력이 낮지만, 귀무가설을 기각하거나 채택하는 결정을 내리는 데 필요한 유의수준을 조정하여 사용됩니다. 비모수검정에는 Sign test, Wilcoxon signed ranks test, Mann Whitney U test, Kruskal Wallis test 등이 있으며, 이러한 검정들은 특정한 분포 가정 없이 데이터의 순위나 부호와 같은 정보를 사용하여 가설을 검정합니다.
결론적으로, 모수검정과 비모수검정은 모집단의 분포 특성과 사용 가능한 데이터의 종류에 따라 선택되어야 하며, 각각의 방법론은 통계적 가설검정에서 중요한 역할을 합니다. 연구자는 표본의 특성과 연구 목적에 맞는 적절한 검정 방법을 선택하여 신뢰성 있는 결론을 도출할 수 있습니다.
Key Word
가설검정, 모수검정, 비모수검정, 정규분포, 순서척도, 명목척도, 데이터종류
모수검정
모수검정(parametric test)은 모집단이 정규분포일 때 주로 수행합니다.
모집단의 확률분포는 일반적으로 평균이 $\mu$ 이고 분산이 $\sigma^2$인 정규분포를 따릅니다. 그리고 표본의 개체들은 모집단의 분포와 동일한 확률분포를 따르므로 표본의 개체도 정규분포를 따릅니다.
$$X_1,X_2,\cdots,X_n \sim {\rm iid} \, N(\mu, \sigma^2)$$
모집단의 분포가 정규분포를 따르면 새로운 확률변수인 표본평균($\bar{X}$)은 평균이 $\mu$이고 분산이 $\dfrac{\sigma^2}{n}$인 정규분포를 따르고 $Z$변환한 확률변수는 표준정규분포를 따릅니다.
$$Z=\dfrac{\bar{X}-\mu}{\dfrac{\sigma}{\sqrt{n}}} \sim {\rm iid} \, N(0, 1)$$
여기서, $n$은 표본크기
표본분산($S^2$)에 $\dfrac{(n-1)}{\sigma^2}$을 곱한 또 다른 새로운 확률변수, $\chi^2$은 표본크기가 $n$인 표본에서는 자유도가 $(n-1)$인 카이제곱분포를 따릅니다.
$$\dfrac{(n-1)S^2}{\sigma^2} \sim \chi_{n-1}^2$$
표본평균($\bar{X}$)을 $Z$변환한 새로운 확률변수($Z$) 식에서 모표준편차($\sigma$)를 알지 못하여 모표준편차를 표본표준편차($S$)로 대치하면 또 다른 새로운 확률변수, $T$가 됩니다. $T$는 자유도 $(n-1)$인 t분포를 따릅니다.
$$\dfrac{\bar{X}-\mu}{\dfrac{\sigma}{\sqrt{n}}} \sim {\rm iid} \, t_{n-1}$$
두 확률변수, $V \sim \chi_{(k)}^2$와 $U \sim \chi_{(m)}^2$가 서로 독립이면 새로운 확률변수, $F$는 자유도가 $k$와 $m$인 F분포를 따릅니다.
$$F=\dfrac{\dfrac{V}{k}}{\dfrac{U}{m}} \sim \chi_{m, k}^2$$
중요한 점은 이상의 모수추정과 모수의 가설검정에서 사용할 새로운 확률변수들은 모두, 정규분포를 따르는 모집단으로부터 추출된 표본통계량 표집의 확률분포입니다.
비모수검정
비모수검정(non-parametric test)은 모집단이 정규분포가 아닐 때 주로 사용합니다.
비모수검정이 필요한 경우
- 모집단의 분포가 정규분포가 아닌 경우 : 이항분포에서의 확률 $p$가 $\dfrac{1}{2}$이 아니어서 왜도가 발생한 경우
- 순서척도 또는 명목척도로 관측한 데이터 : 이산형 독립변수(설명변수)의 간격을 모르고 순서만 아는 경우
- 데이터의 수가 작은 경우 : 두 표본크기 $n_1$과 $n_2$가 작은 경우
비모수검정의 단점
모평균에 대한 비모수검정
- 1표본인 경우 : 1표본은 전체 모집단에서 추출하거나 설계한 표본이 모집단의 범주(category, 수준, level)가 없어 1개인 경우를 말함니다.
♦ Sign test
♦ Wilcoxon signed ranks (대응표본 t검정의 비모수검정, the non-parametric version of matched samples t-test) - 2표본인 경우 : 2표본은 전체 모집단에서 추출하거나 설계한 표본이 모집단의 범주가 2개여서 2개의 표본이 생성된 경우를 말합니다.
♦ Mann Whitney U test (독립표본 t검정의 비모수검정, the Wilcoxon rank sum test)
♦ the Mann Whitney Wilcoxon test (범주가 2개인 F검정의 비모수검정) - 여러 표본인 경우 : 여러 표본은 전체 모집단에서 추출하거나 설계한 표본이 모집단의 범주가 2개 이상이어서 2개 이상의 표본이 생성된 경우를 말합니다.
♦ Kruskal Wallis test (범주가 여러 개인 F검정의 비모수검정)
Sign Test(부호검정)
부호검정은 분포의 중앙값에 대하여 검정하는 기법입니다. 부호검정의 귀무가설은 다음과 같습니다.
귀무가설($H_0$) : 모평균=중앙값
표본데이터 값이 중앙값보다 크면 +부호를 작으면 – 부호를 부여합니다. +의 개수와 –의 개수가 비슷하면 귀무가설을 기각하지 못하고 차이가 나면 귀무가설을 기각합니다. + 값이 나오는 개수를 $X$ 라 하면 확률변수 $X$ 는 이항분포를 따릅니다.
$$X \sim Bin(n,p)$$
귀무가설이 채택되면
$$p=\dfrac{1}{2}$$
따라서 $X=x$ 라면 이항분포의 확률을 구하고, 유의수준과 비교하여 판정합니다.
Mann Whitney U test (독립표본 t검정의 비모수검정, the Wilcoxon rank sum test)
두 표본크기 $n_1$과 $n_2$가 작을 때 적용합니다. 여기서, $n_1$은작은 집단의 크기,$n_2$는큰 집단의 크기입니다. 검정순서는 다음과 같습니다.
Step 1 : 순서대로 나열하고 순서 매기기
Step 2 : 표본의 크기가 다른 경우, 크기가 작은 집단의 순위 합계($T$) 구하기
Step 3 : Wilcoxson rank sum test 를 위한 하한 경계치 $T_{\alpha}$값 찾기
Step 4 : 상한치 구하기 $n_1(n_1+n_2+1)−T_{\alpha}$
Step 5 : 판정
Mann Whitney Wilcoxon test (범주가 2개인 F검정의 비모수검정)
Step 1 : 순서대로 나열하고 순서 매기기(Wilcoxon rank sum test 와 동일)
Step 2 : $\chi^2$값을 구해서 자유도가 1인 카이제곱 분포의 기준과 비교하고 판정
Kruskal-Wallis test (범주가 여러개인 F검정의 비모수검정)
Kruskal-Wallis test는 표본이 2개 이상이고 표본의 모집단이 정규분포를 따른다는 가정을 할 수 없는 경우, 표본이 2개 이상인 경우의 모수검정인 일원분산분석 대신 적용합니다. Kruskal-Wallis test를 할 때, 서로 다른 모집단에서 추출한 표본이 독립적이고 동일한 연속형 확률분포이지만 정규분포를 따르지 않는다고 가정합니다.
가정 : 서로 다른 모집단에서 추출한 표본이 독립적이고 동일한 연속형 확률분포이지만 정규분포를 따르지 않는다
귀무가설($H_0$) : 모든 모집단의 중앙값이 동일함
대립가설($H_1$) : 최소한 하나의 중앙값이 다름
Terminology
데이터
데이터는 질적 또는 양적 변수값의 집합입니다. 데이터와 정보 또는 지식은 종종 같은 의미로 사용하지만 데이터를 분석하면 정보가 된다고 볼 수 있습니다. 데이터는 일반적으로 연구의 결과물로 얻어집니다. 한편, 데이터는 경제(매출, 수익, 주가 등), 정부(예 : 범죄율, 실업률, 문맹율)와 비정부기구(예 : 노숙자 인구 조사)등 다양한 분야에서도 나타납니다. 그리고 데이터를 수집 및 분석하고 시각화할 수 있습니다.
일반적인 개념의 데이터는 응용이나 처리에 적합한 형태로 표현되거나 코딩됩니다. 원시 데이터 (“정리되지 않은 데이터”)는 “정리”되기 전의 숫자 또는 문자의 모음입니다. 따라서 데이터의 오류를 제거하려면 원시 데이터에서 데이터를 수정해야 합니다. 데이터 정리는 일반적으로 단계별로 이루어지며 한 단계의 “정리 된 데이터”는 다음 단계의 “원시 데이터”가 됩니다. 현장 데이터는 자연적인 “현장”에서 수집되는 원시 데이터입니다. 실험 데이터는 관찰 및 기록을 통한 과학적 조사에서 생성되는 데이터입니다. 데이터는 디지털 경제의 새로운 자원입니다.
출처
Reference
본인의 Google 계정으로 구글시트를 복사
=COUNTA(B3:B22) : B3~B22 행의 범위에 있는 데이터의 개수
=COUNT(C3:C22) : C3 ~C22 행의 범위에 숫자 데이터의 개수