[DATA SCIENCE]
데이터사이언스 > 모델링 > 통계모델 > 표본통계량 표집
표본평균의 표집

[Q&A]
새로운 확률변수는 무엇
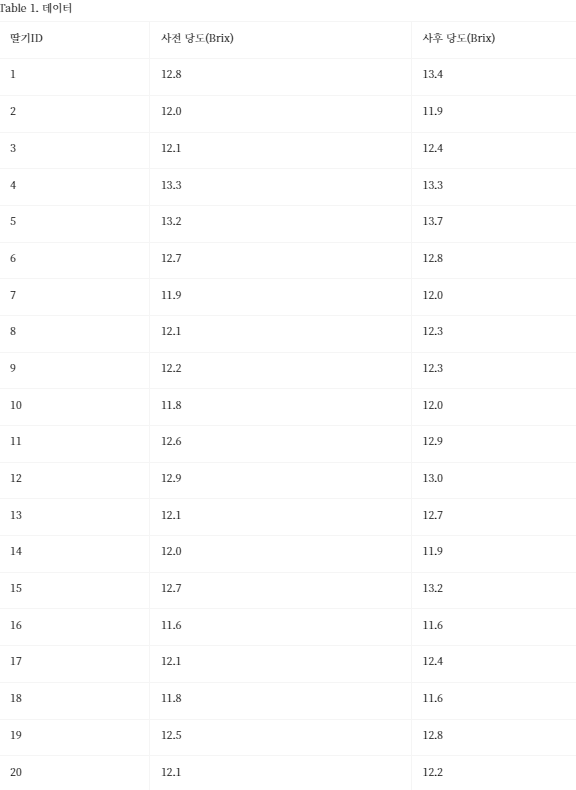
초등학생의 보드게임 사전과 사후의 수학적 창의력 점수 차이입니다.
귀무가설은 기준을 생성하는가
절대 0이 없는 간격척도로 구한 데이터를 비교할 수 있게 해줍니다.
차이평균의 귀무가설과 원점의 관계는
귀무가설에서의 “0”은 두 모집단의 평균 차이가 없음을 나타내며, 이는 통계적으로 “원점” 또는 “기준점”으로 간주합니다.
대응표본과 독립표본에서 새로운 확률변수를 확률변수값의 차이라고 할 때 어느 표본의 분산이 더 큰가
일반적으로 독립표본에서의 새로운 확률변수의 분산이 대응표본에서의 새로운 확률변수의 분산보다 더 크다고 할 수 있습니다. 이는 독립표본의 경우 두 모집단의 변동성이 모두 분산에 기여하기 때문입니다.
표준편차는 단위가 될 수 있는가
표준편차의 단위는 데이터의 원 단위를 유지하기 때문에, 그것을 데이터 집합의 변동성을 나타내는 ‘단위’로 사용할 수 있습니다. 결론적으로, 표준편차를 단위로 사용하는 것은 엄밀히 말하면 정확하지 않지만, 특정 상황에서는 유용하게 활용될 수 있습니다. 사용 전에 주의 사항을 숙지하고, 필요에 따라 다른 방법을 함께 사용하는 것이 바람직합니다.
대응표본과 독립표본은 무엇이 다른가
독립표본은 독립된 두개 이상의 범주를 가집니다. 대응표본은 개체로 연결되어 있으며 같은 시간이나 공간의 이동으로 같은 개체의 속성변동을 반영합니다.
ARTICLE CONTENTS
Sampling of the sample mean
Author
박근철![]() , 양윤원
, 양윤원![]()
DocuHut Co. Ltd., Seoul, Republic of Korea
Citation
Park GC, Yang YW. Data Type. Data Science 2024;1:1.
Publication History
Received: 31 March 2023, Revised: 30 April 2023, Accepted: 04 May 2023, Published: 19 May 2023
Publication Information
DOI : 24711
데이터사이언스, Vol, Issue,
Abstract
표본평균 표집은 모평균 추정 및 가설검정에 쓰이며, 신뢰구간과 유의수준을 설정하여 모평균의 위치를 추정합니다. 신뢰구간은 주어진 신뢰수준(예: 90%, 95%) 하에서 모평균이 위치할 범위를 나타내고, 가설 검정 시 유의수준(예: 5%, 1%)을 설정하여 표본평균과 모평균의 관계를 검증합니다. 표본평균의 속성으로 불편성, 일치성, 유효성이 있으며, 이는 표본평균이 모평균을 잘 추정하는 지를 나타내는 성질입니다. 표본평균의 표집분포는 표본에서 나온 통계량의 확률분포이며, 중심극한정리에 따라 이 분포는 수학적 모델링이 가능합니다. 이러한 방법은 모집단 모형과 표본 모형을 기반으로 하며, 모분산을 표본크기로 나눈 값으로 표본평균 표집의 분산을 유도합니다.
Key Word
통계량, 표본평균, 표집, 표집분포, 모평균, 신뢰수준, 신뢰구간, 추정, 가설검정, 표본평균 표집의 분산
표본평균 표집의 적용 예
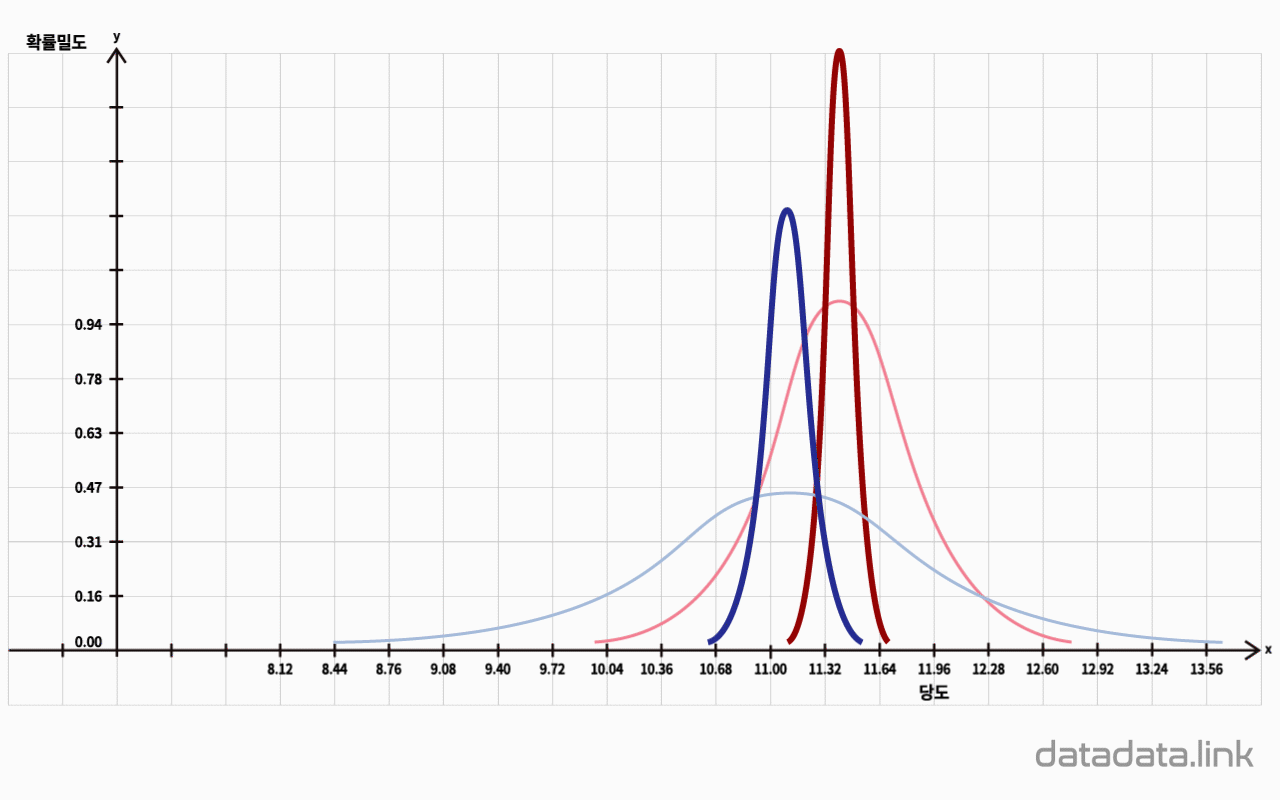
표본평균 표집은 표본이 추출된 집단(모집단)의 모평균을 추정하거나 모평균에 대한 가설을 검정할 때 사용합니다. 모평균을 추정할 때는 표본평균 추정량을 통해 구한 표본평균을 기준으로 하고, 표본평균의 표준오차와 주어진 신뢰수준으로 정해지는 구간사이에 모평균이 위치한다고 추정합니다. 신뢰구간을 정하기 위해서는 신뢰수준을 주어야 합니다. 신뢰수준은 90%, 95%, 99%, 99.9% 등 확률단위를 가지며 검정하는 주체가 결정합니다. 표본평균을 중심으로 신뢰수준의 확률을 가지는 구간을 신뢰구간이라고 합니다. 만일, 표본평균의 확률분포를 안다면 신뢰수준으로 신뢰구간을 알 수 있습니다. 신뢰구간은 확률변수의 단위와 같습니다.
반면, 표본평균과 모평균의 관계(예를들면 표본평균과 모평균이 같다는 영가설, 귀무가설)를 검정할 때는 표본평균과 모분산(모분산을 모르는 경우에는 표본분산을 사용)으로 모평균에 대한 가설을 검정합니다. 검정을 하려면 신뢰수준의 반대개념인 유의수준을 검정의 주체가 결정해야합니다. 유의수준은 확률이고 따라서 단위는 확률의 단위와 같습니다. 보통 10%, 5%, 1%, 0.1% 등이 사용됩니다. 만일 표본평균의 확률분포를 안다면 유의수준으로 유의구간을 구할 수 있습니다. 유의구간은 보통 최소값($-\infty$)에서 임계값까지 또는 임계값에서 최대값($+\infty$)으로 나타납니다.
정리하면 표본평균으로 모평균을 추정할 때는 신뢰구간을 사용하며, 표본평균과 모평균을 비교하는 가설을 검정할 때는 표본평균으로구한 유의확률과 유의수준을 비교합니다. 확률변수인 표본평균이 나타내는 확률분포를 표본평균의 표집분포(sampling distribution)라고 합니다. 이는 표본의 확률분포(sample distribution)와 구분됩니다.
표본평균의 속성은 다음 세가지가 있습니다.
1) 불편성 : 모평균에 대해 편향되지 않는다. 즉 표본평균의 기대값은 모평균과 같다.
2) 일치성 : 표본크기를 늘리면 집단에서 추출한 표본의 표본평균은 집단의 모평균과 점점 같아진다. 일반화하면, 표본통계량은 집단의 모수와 점점 같아진다.
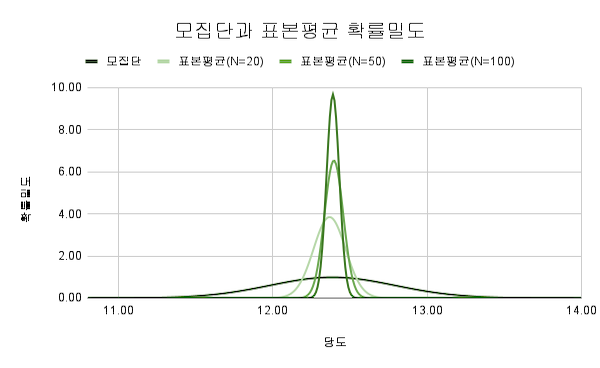
3) 유효성 : 추정량 중에서 최소의 분산을 가진 추정량이 가장 효율적이다. 표본크기를 늘리면 표본평균 표집의 분산이 점점 작아진다.
표본평균 표집
표본평균 표집((sampling distribution)의 원소는 표본평균(sample mean)입니다.
모집단 모델
$$\{{X_1},\ldots ,{X_N}\}$$
여기서, $N$은 모집단크기 : 모집단이 무한집단이면 $N→∞$
표본 모델
확률변수 $X$를 가지는 개체($i$)가 이루는 집단($X_i$)에서 추출한 표본
$$\{{X_1},\ldots ,{X_n}\}$$
여기서, $n$은 표본크기
표본평균($\bar X$) 표집 모델
$$\{{{\bar X}_1},\ldots ,{{\bar X}_k}\}$$
여기서, $k$는 표집크기 : 표집이 무한집단이면 $k→∞$
표본평균의 추정량(estimator)
$${\bar X}=\dfrac {X_{1}+X_{2}+\cdots +X_{n}}{n}=\dfrac{1}{n}\sum\limits_{i=1}^{n}X_i$$
여기서, $n$은 표본크기
표본분산의 추정량(estimator)
$$S_X^2= \dfrac {({X_1}-{\bar X})^2+({X_2}-{\bar X})^2+ \cdots +({X_n}-{\bar X})^2}{n-1}=\dfrac{1}{n-1}\sum\limits_{i=1}^{n}({X_i}-{\bar X})^2$$
여기서, $n$은 표본크기
표본평균 표집의 평균 : 표본평균의 분포의 무게중심
$$\mu_{\bar X}={\rm E} [\bar X]=\mu_X$$
여기서, $\mu_X$는 모평균 : $\mu_X={\rm E}[X]$
$n$은 표본크기
표본평균 표집의 분산 : 표본평균의 변동
$${\rm Var}[\bar X]=\sigma_{\bar X}^2=\dfrac{\sigma_X ^2}{n}$$
여기서, $n$은 표본크기
$\sigma_X^2$은 모분산
표본평균 표집의 표준편차
$${\rm SD}[\bar X]=\sigma_{\bar X}=\sqrt{\dfrac{\sigma_X ^2}{n}}=\dfrac{\sigma_X}{\sqrt{n}}$$
$n$은 표본크기
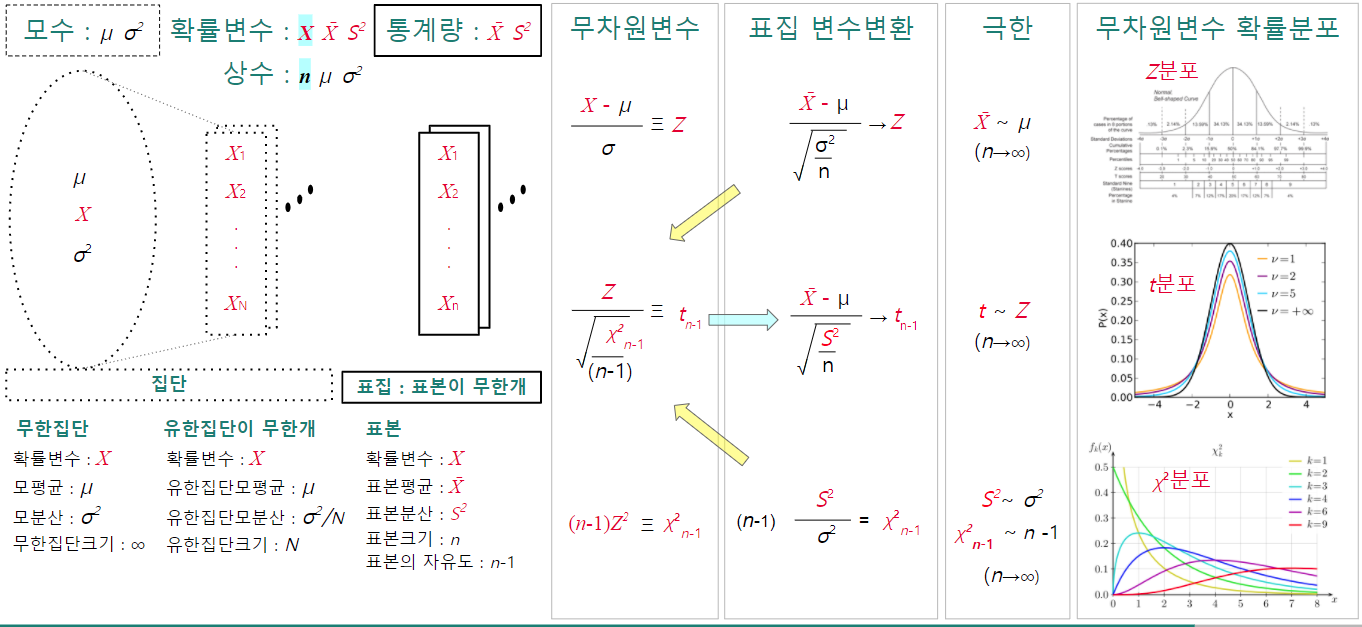
표본평균($\bar X$)을 $Z$변환
$$Z=\dfrac{{\bar X}-\mu_X}{\dfrac{\sigma_X}{\sqrt{n}}}∼{\rm N}(0, 1)$$
여기서, $\mu_X$는 모평균
${\rm N}(0, 1)$는 표준정규분포
$\mu_X=\mu_{\bar X}$
$n$은 표본크기
표본평균($\bar X$)을 $t$변환
$$t=\dfrac{\bar X-\mu_X}{\dfrac{S_X}{\sqrt{n}}}∼t_{n-1}$$
여기서, $\mu_X$는 모평균
$S_X$는 표본표준편차
$t_{n-1}$은 자유도가 $n-1$인 $t$분포
$n$은 표본크기
표본평균 표집의 평균과 분산
크기가 1인 표본의 속성
크기가 $n$인 표본의 속성
집단에서 랜덤하게 추출된 크기가 $n$인 표본을 집합으로 표현할 때, 집합의 원소인 각 확률변수(${X_1}, {X_2}, … , {X_n}$)는 서로 독립이며, 각 확률변수의 확률분포는 동일하며, 집단이 무한집단인 경우, 집단의 분포와 동일하다고 할 수 있습니다.
다음식과 같이 각 원소의 기대값은 모평균과 같습니다.
$${\rm E}[X_1]={\rm E}[X_2]= … = {\rm E}[X_n] = \mu_X$$
다음식과 같이 각 원소의 분산의 기대값은 모분산과 같습니다.
$${\rm E}\left[{\rm Var}[X_1]\right]={\rm E}\left[{\rm Var}[X_2]\right]= … = {\rm E}\left[{\rm Var}[X_n]\right] = \sigma_X^2$$
다음식과 같이 각 원소의 표준편차의 기대값은 모분산과 같습니다.
$${\rm E}\left[{\rm SD}(X_1)\right]={\rm E}\left[{\rm SD}(X_2)\right]= … = {\rm E}\left[{\rm SD}(X_n)\right] = \sigma_X$$
그리고 표본평균은 다음과 같습니다.
$$\bar X=\dfrac{{X_1}+{X_2}+ … + {X_n}}{n}=\dfrac{1}{n}{X_1}+\dfrac{1}{n}{X_2}+ … + \dfrac{1}{n}{X_n}$$
표본평균 표집의 평균과 모평균이 같음을 증명
표본평균 표집의 평균, 즉, 표본평균의 기대값은 모평균과 같음을 다음과 같이 증명합니다.
$$\eqalign { {\rm E}[\bar X]&={\rm E}\left[\dfrac{1}{n}{X_1}+\dfrac{1}{n}{X_2}+ … + \dfrac{1}{n}{X_n}\right]\cr &=\dfrac{1}{n}\left({\rm E}[X_1]+{\rm E}[X_2]+ … + {\rm E}[X_n]\right)\cr &=\dfrac{1}{n}\left(\mu_{X_1}+\mu_{X_2}+ … + \mu_{X_n}\right)\cr &=\dfrac{1}{n}\left(n\mu_{X}\right)=\mu_X }$$
표본평균 표집의 분산 유도
표본평균 표집의 분산(표본평균 표준오차의 제곱)은 다음과 같이 유도되며 모분산을 표본크기로 나눈 값입니다.
$$\eqalign { {\rm Var}[\bar X]&={\rm Var}\left[\dfrac{1}{n}{X_1}+\dfrac{1}{n}{X_2}+ … + \dfrac{1}{n}{X_n}\right]\cr &=\dfrac{1}{n^2}\left({\rm Var}[X_1]+{\rm Var}[X_2]+ … + {\rm Var}[X_n]\right)\cr &=\dfrac{1}{n^2}\left(\sigma_X^2+\sigma_X^2+ … + \sigma_X^2\right)\cr &=\dfrac{1}{n^2}\left(n\sigma_{X}^2\right)=\dfrac{\sigma_X^2}{n} }$$
집단모형과 표집모형
표본통계량의 표집분포는 집단에서 일정한 크기로 뽑을 수 있는 모든 표본을 뽑았을 때, 그 모든 표본의 특성치인 표본통계량의 확률분포입니다. 표본통계량의 표집분포에는 표본평균의 표집분포, 표본분산의 표집분포, 표본비율의 표집분포가 있습니다. 그리고 중심극한정리에 의해 표본통계량의 표집분포는 모두 수학적인 모델링이 가능한 분포를 나타냅니다.
Terminology
모수
통계적 매개변수(모수, parameter) 또는 집단의 매개변수는 통계 또는 확률변수의 확률분포를 표현하는 양입니다. 그것은 통계의 대상인 집단이나 통계적 모델의 수치적 특성으로 간주 될 수 있습니다. 구분된 데이터 계열(family)이 있다고 가정합니다. 구분자(index)가 계열의 매개변수이면 이 계열은 매개변수화된 계열입니다. 예를 들어, chi-squared 분포의 계열은 자유도의 수에 의해 구분(indexing)될 수 있습니다. 자유도의 수는 카이제곱분포의 매개변수이므로 카이제곱분포는 매개변수화된 계열이라고 할 수 있습니다.
출처
표준오차
통계에서 표준오차(standard of error)은 일반적으로 모수(매개변수, parameter)의 추정치입니다. 표준오차는 표집 분포의 표준편차 또는 모표준편차의 추정치입니다. 모수 또는 통계량이 평균인 경우는 평균의 표준오차(standard error of mean)라고 합니다.
집단의 표본평균 분포는 반복적으로 표본을 추출하고 표본평균값을 기록함으로써 생성됩니다. 이것은 다른 확률분포를 형성하며,이 분포는 고유한 평균과 분산을 갖습니다. 수학적으로 얻은 표본 분포의 분산은 집단의 분산을 표본크기로 나눈 값과 같습니다. 이는 표본크기가 증가함에 따라 표본평균이 집단의 평균에 더 밀접하게 밀집되기 때문입니다. 따라서 표준오차와 표준편차 사이의 관계는 주어진 표본 크기에 대해 표준오차가 표준편차를 표본크기의 제곱근으로 나눈 것과 같습니다. 즉, 평균의 표준오차는 집단의 평균을 중심으로 주위에 분포하는 표본평균의 분산의 척도입니다.
회귀분석에서 “표준오차”라는 용어는 특정 회귀계수의 신뢰구간에서 사용되며 카이제곱 통계량의 제곱근을 나타냅니다.
출처처
Reference
본인의 Google 계정으로 구글시트를 복사
=COUNT(D3:D1002) : 데이터 개수. D3에서 D1002에 있는 숫자로 표시된 데이터의 개수.
=AVERAGE(D3:D1002) : 평균. D3에서 D1002에 있는 데이터의 평균.
=VARP(D3:D1002) : 모분산. D3에서 D1002에 있는 데이터의 모분산. 편차제곱합을 데이터 개수로 나눔.
=STDEV.P(D3:D1002) : 모표준편차. D3에서 D1002에 있는 데이터의 모표준편차. 모분산의 제곱근.
=NORMDIST(P3,G3,I3,FALSE) : 정규분포 확률밀도. G3가 평균, I3가 표준편차인 정규분포에서 P3 확률변수에 대한 확률밀도. FALSE를 TRUE로 변경하면, 누적확률밀도를 계산함.
=ROWS(K2:K2) : 지정된 배열 또는 범위에 있는 행의 개수.
=RANDBETWEEN(1,1000) : 두 값 사이(두 값 포함)의 고르게 분산된 정수인 난수를 반환.
=INDIRECT(I3&”:”&J3) : 문자열로 지정된 셀 참조를 반환.
=COUNTIF(K2:K2, ROW(I3:J3)) : 범위에서 조건에 맞는 개수를 표시.
=NOT(논리표현식) : 논리 값의 역을 반환.
=LARGE(데이터집합, n) : 데이터 집합에서 n번째로 큰 요소를 반환.
=ARRAYFORMULA : 배열 수식에서 여러 행 또는 열에 반환된 값을 표시.
=ARRAY_CONSTRAIN : 배열 결과를 지정된 크기로 제한.
=VLOOKUP(M3,A:B,2,FALSE) : 열 방향 검색. A:B열의 첫 번째 열에서 M3값이 있는 행의 2번째 값을 표시합니다. FALSE를 입력하면, 완전히 일치된 값만 표시합니다. FALSE가 아닌 TRUE를 입력하면, H3에 근접한 값(H3보다 작거나 같은 값)이 있는 행의 2번째 값을 표시합니다.
=VAR.S(BG3:BG22) : 표본분산. BG3에서 BG22에 있는 데이터의 표본분산. 편차제곱합을 데이터 개수 -1로 나눔.
=STDEV.S(BG3:BG22) : 표본표준편차. BG3에서 BG22에 있는 데이터의 표본표준편차. 표본분산의 제곱근.